DL| Pytorch
Pytorch(tensorflow 차이, 연산, 구성요소, 클래스, ray,…)
- Pytorch VS TensorFlow
- Pytorch Operations
- AutoGrad(pytorch의 자동 미분 엔진)
- Torch 구성요소
- Pytorch datasets & dataloaders
- Model
- pretrained model Transfer learning
- Monitoringtools for PyTorch
- Multi-GPU
- Hyperparameter Tuning
- PyTorch Troubleshooting
Pytorch VS TensorFlow
Pytorch: Dynamic Computation Graph(연산의 과정을 그래프로 표현)
Tensorflow: Define and Run(그래프를 먼저 정의 → 실행 시점에 데이터 feed)

Why Pytorch
→ Numpy + AutoGrad + Function
- Define by Run의 장점
- 즉시 확인 가능 → pythonic code
- GPU support, Good API and Community
- 사용하기 편한 장점이 큼
- TF는 production과 scalability의 장점
- Numpy 구조를 가지는 Tensor 객체로 array 표현
- 자동미분을 지원하여 DL 연산을 지원
- 다양한 형태의 DL을 지원하는 함수와 모델을 지원함
Pytorch Operations
- Numpy + Autograd
Tensor
- 다차원 Arrays를 표현하는 PyTorch 클래스
- 사실상 Numpy의 ndarray와 동일(TensorFlow의 Tensor와도 동일)
- Tensor를 생성하는 함수도 동일
Array to Tensor
# data to tensor
data = [[3, 5], [10, 5]]
x_data = torch.tensor(data)
# ndarray to tensor
nd_array_ex = np.array(data)
tensor_array = torch.from_numpy(nd_array_ex)
Tensor data types
기본적으로 tensor가 가질 수 있는 data 타입은 numpy와 동일
numpy likes operations
- 기본적으로 Pytorch의 대부분의 사용법이 그대로 적용
- pytorch의 tensor는 GPU에 올려서 사용가능
tensor handling
view, squeeze, unsqueeze 등으로 tensor 조정 가능
- view: reshape과 동일하게 tensor의 shape을 변환
- squeeze: 차원의 개수가 1인 차원을 삭제(압축)
- unsqueeze: 차원의 개수가 1인 차원을 추가
view
tensor_ex = torch.rand(size=(2, 3, 2))
tensor_ex
# tensor([[[0.7466, 0.5440],
# [0.7145, 0.2119],
# [0.8279, 0.0697]],
# [[0.8323, 0.2671],
# [0.2484, 0.8983],
# [0.3228, 0.2254]]])
tensor_ex.view([-1, 6])
# tensor([[0.7466, 0.5440, 0.7145, 0.2119, 0.8279, 0.0697],
# [0.8323, 0.2671, 0.2484, 0.8983, 0.3228, 0.2254]])
tensor_ex.reshape([-1, 6])
# tensor([[0.7466, 0.5440, 0.7145, 0.2119, 0.8279, 0.0697],
# [0.8323, 0.2671, 0.2484, 0.8983, 0.3228, 0.2254]])
→ view와 reshape은 contiguity 보장의 차이
reshape은 a와 b의 메모리가 공유되지 않으므로 b는 변경되지 않음
a = torch.zeros(3, 2)
b = a.view(2, 3)
a.fill_(1)
'''
a
tensor([[1., 1.],
[1., 1.],
[1., 1.]])
b
tensor([[1., 1., 1.],
[1., 1., 1.]])
'''
a = torch.zeros(3, 2)
b = a.t().reshape(6)
a.fill_(1)
'''
a
tensor([[1., 1.],
[1., 1.],
[1., 1.]])
b
tensor([0., 0., 0., 0., 0., 0.])
'''
squeeze, unsqueeze
- squeeze: 차원이 1인 차원 제거
- unssqueeze: squeeze 함수의 반대로 1인 1차원을 생성
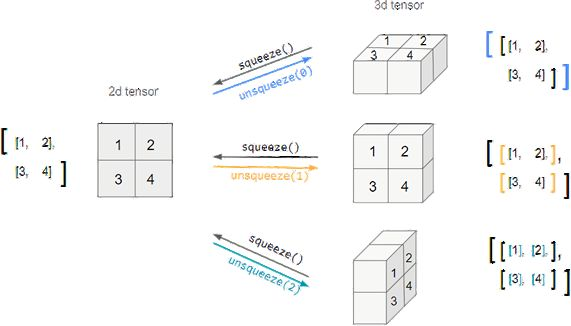
tensor_ex = torch.rand(size=(2,1,2))
tensor_ex.squeeze()
# tensor([[0.8510, 0.8263],
# [0.7602, 0.1309]])
tensor_ex = torch.rand(size=(2,2))
tensor_ex.unsqueeze(0).shape
# torch.Size([1,2,2])
tensor_ex.unsqueeze(1).shape
# torch.Size([2,1,2])
tensor_ex.unsqueeze(2).shape
# torch.Size([2,2,1])
행렬곱셈 연산 mm vs matmul
n2 = np.arange(10).reshape(5, 2)
t2 = torch.FloatTensor(n2)
t1.mm(t2)
# tensor([[ 60., 70.],
# [160., 195.]])
t1.dot(t2)
# RuntimeError
t1.matmul(t2)
# tensor([[ 60., 70.],
# [160., 195.]])
a = torch.rand(10)
b = torch.rand(10)
a.dot(b)
a = torch.rand(10)
b = torch.rand(10)
a.mm(b)
→ mm과 matmul은 broadcasting 지원 차이
- mm은 정확하게 matrix 곱의 사이즈가 맞아야 사용이 가능
matmul은 T1(10, 3, 4)와 T2(4)를 곱할 때
맨 앞의 dim이 3개일 때는 첫 dim을 batch로 간주하고 T1(3, 4) tensor의 10개의 batch와 T2(4)랑 곱을 해주는 것임
tensor operations for ml/dl formula
nn.functional 모듈을 통해 다양한 수식 변환을 지원함
AutoGrad(pytorch의 자동 미분 엔진)
Pytorch Tutorial torch autograd에 대한 간단한 소개 • Autograd ; Automatic gradient calculating API
pytorch의 핵심은 자동 미분의 지원! → backword 함수를 사용
w = torch.tensor(2.0, requires_grad=True)
y = w**2
z = 10*y + 25
z.backward()
w.grad
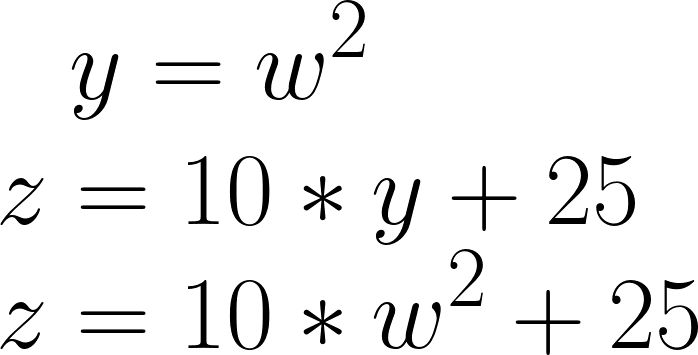
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 – b**2
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
a.grad
# a.grad
b.grad
# tensor([-12., -8.])
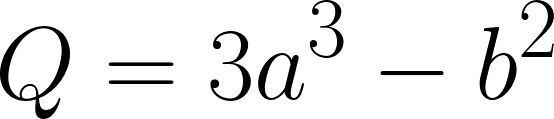
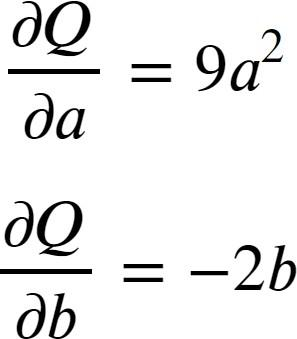
Torch 구성요소
torch.nn.Module
- 딥러닝을 구성하는 layer의 base class
- input, output, forward, backward 정의
- 학습의 대상이 되는 parameter(tensor) 정의
nn.Parameter
- Tensor 객체의 상속 객체
- nn.Module 내에 attribute가 될 때는 required_grad = True로 지정되어 학습 대상이 되는 Tensor
- 우리가 직접 지정할 일은 잘 없고 대부분의 layer에는 weights 값들이 지정되어 있음
Backward
- Layer에 있는 Parameter들의 미분을 수행
- Forward의 결과값(model의 output=예측치)과 실제값간의 차이(loss)에 대해 미분을 수행
- 해당 값으로 Parameter 업데이트
실제 backward는 Module 단계에서 직접 지정가능
- Module에서 backward 와 optimizer 오버라이딩
- 사용자가 직접 미분 수식을 써야하는 부담 → 쓸 일은 없으나 순서를 이해할 필요는 있음
class LR(nn.Moudule):
def __init__(self, dim, lr = torch.scalar_tensor(0.01)):
super(LR, self).__init__()
# initialize parameters
self.w = torch.zeros(dim, 1, dtype=torch.float).to(device)
self.b = torch.scalar_tensor(0).to(device)
self.grads = {'dw':torch.zeros(dim, 1, dtype=torch.float).to(device),
'db':torch.scalar_tensor(0).to(device)}
self.lr = lr.to(device)
def forward(self, x):
# compute forward
z = torch.mm(self.w.T, x)
a = self.sigmoid(z)
return z
def sigmoid(self, z):
return 1 / (1 + torch.exp(-z))
def backward(self, x, yhat, y):
## compute backward
self.grads['dw'] = (1/x.shape[1]) * torch.mm(x, (yhat-y).T)
self.grads['db'] = (1/x.shape[1]) * torch.sum(yhat-y)
def optimize(self):
## optimization step
self.w = self.w - self.lr * self.grads['dw']
self.b = self.b - self.lr * self.grads['db']
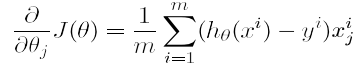
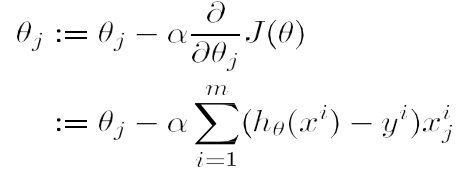
Pytorch datasets & dataloaders
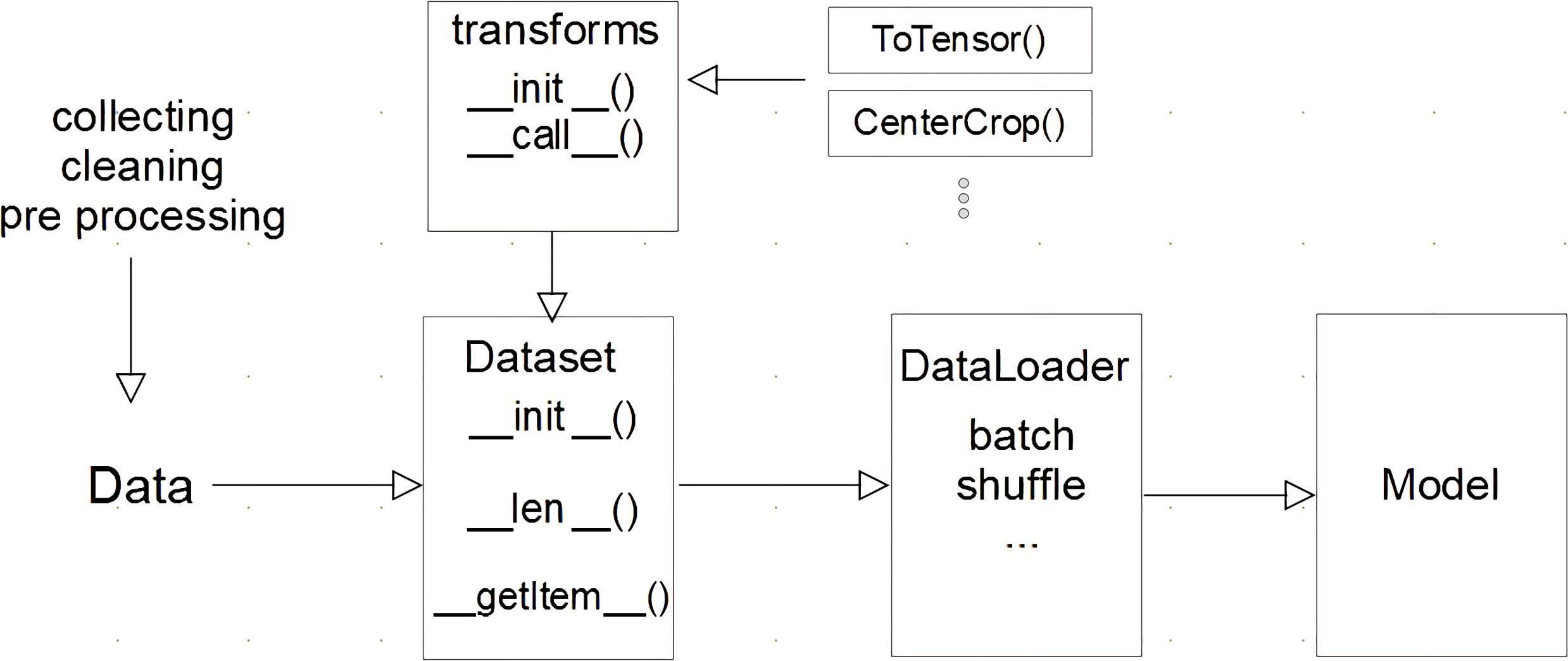
Dataset 클래스
- 데이터 입력 형태를 정의하는 클래스
- 데이터를 입력하는 방식의 표준화
- Image, Text, Audio등에 따른 다른 입력 처리
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, text, labels):
self.labels = labels
self.data = text
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
label = self.labels[idx]
text = self.data[idx]
sample = {"Text":text, "Class":label}
return sample
Dataset 클래스 생성시 유의사항
- 데이터 형태에 따라 각 함수를 다르게 정의
- 모든 것을 데이터 생성 시점에 처리할 필요 없음: image의 Tensor 변화는 학습에 필요한 시점에 변환
- 데이터 셋에 대한 표준화된 처리방법 제공 필요: 후속 연구자 또는 동료에게는 빛과 같은 존재
- 최근에는 HuggingFace 등 표준화된 라이브러리 사용
DataLoader 클래스
- Data의 Batch를 생성해주는 클래스
- 학습직전(GPU feed전) 데이터의 변환을 책임
- Tensor로 변환 + Batch 처리가 메인 업무
- 병렬적인 데이터 전처리 코드의 고민 필요
# Dataset 생성
text = ['Happy', 'Amazing', 'Sad', 'Unhappy', 'Glum']
labels = ['Positive', 'Positive', 'Negative', 'Negative', 'Negative']
MyDataset = CustomDataset(text, labels)
MyDataLoader = DataLoader(MyDataset, batch_size=2, shuffle=True)
next(iter(MyDataLoader))
# {‘Text’: ['Glum', ‘Sad'], 'Class': ['Negative', 'Negative’]}
# DataLoader Generator
MyDataLoader = DataLoader(MyDataset, batch_size = 2, shuffle = True)
for dataset in MyDataLoader:
print(dataset)
# {‘Text’: ['Glum', 'Unhappy'], 'Class': ['Negative', 'Negative’]}
# {‘Text’: [‘Sad', ‘Amazing'], 'Class': ['Negative', ‘Positive’]}
# {‘Text’: [‘happy'], 'Class': [‘Positive']}
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
Model
model.save()
- 학습의 결과를 저장하기 위한 함수
- 모델 형태(architecture)와 파라메터를 저장
- 모델 학습 중간 과정의 저장을 통해 최선의 결과모델을 선택
- 만들어진 모델을 외부 연구자와 공유하여 학습 재연성 향상
# state_dict: 모델의 파라미터를 표시
print("Model's state_dict:")
for param_tensor in model.state_dict():
print(param_tensor, "\t", model.state_dict()[param_tensor].size())
# 모델의 파라미터를 저장
torch.save(model.state_dict(),
os.path.join(MODEL_PATH, "model.pt"))
# 같은 모델의 형태에서 파라미터에만 load
new_model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join(
MODEL_PATH, "model.pt")))
# 모델의 architecture와 함께 저장
torch.save(model, os.path.join(MODEL_PATH, "model.pt"))
# 모델의 architecture와 함께 load
model = torch.load(os.path.join(MODEL_PATH, "model.pt"))
checkpoints
- 학습의 중간결과를 저장하여 최선의 결과를 선택
- earlystopping 기법 사용시 이전학습의 결과물을 저장
- loss와 metric값을 지속적으로 확인 저장
- 일반적으로 epoch,loss,metric을 함께 저장하여 확인
- colab에서 지속적인 학습을 위해 필요
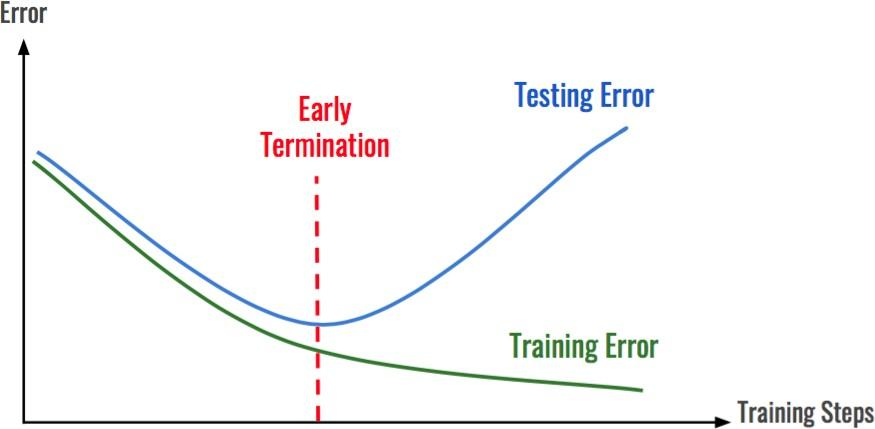
torch.save({
'epoch': e,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': epoch_loss
},
f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt")
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
pretrained model Transfer learning
Transfer learning
- 다른 데이터셋으로 만든 모델을 현재 데이터에 적용
- 일반적으로 대용량 데이터셋으로 만들어진 모델의 성능↑
- 현재의 DL에서는 가장 일반적인 학습 기법
- backbone architecture가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행함
Freezing
- pretrained model을 활용시 모델의 일부분을 frozen 시킴
- 보통 데이터의 특징을 추출하는 부분의 변수는 동결하고, 분류 파트에 해당하는 fully connected layer의 변수만 업데이트할 수 있음
# vgg16 모델을 vgg에 할당하기
vgg = models.vgg16(pretrained=True).to(device)
# 모델에 마지막 Linear Layer 추가하기
class MyNewNet(nn.Module):
def _init_(self):
super(MyNewNet, self).__init_()
self.vgg19 = models.vgg19(pretrained=True)
self.linear_layers = nn.Linear(1000, 1)
# Defining the forward pass
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)
# 마지막 레이어 제외하고 frozen
for param in my_model.parameters():
param.requires_grad = False
for param in my_model.linear_layers.parameters():
param.requires_grad = True
Monitoringtools for PyTorch
tensorboard, weight&biases
Multi-GPU
Model parallel
다중 GPU에 학습 분산하기
모델 나누는 것은 alexnet 때부터 사용
모델의 병목, 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제
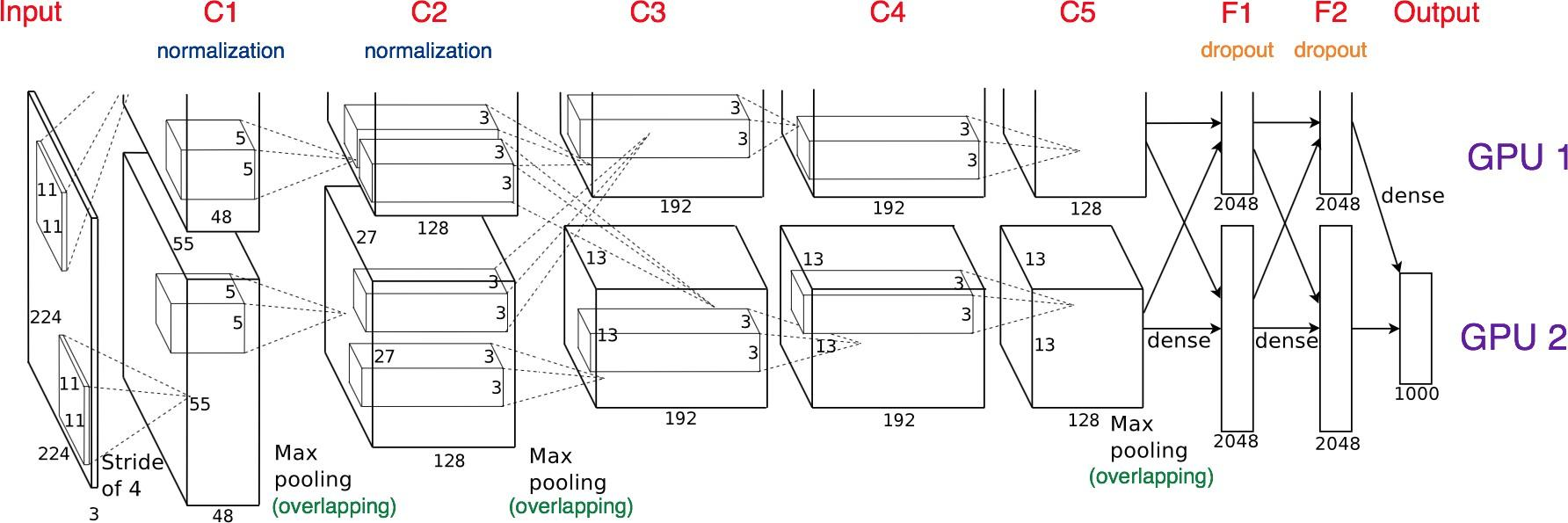
class ModelParallelResNet50(ResNet):
def __init__(self, **args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes = num_classes, *args, **kwargs)
self.seq1 = nn.Sequential(
self.conv1, self.bn1, self.relu, self.maxpool, self.layer1, self.layer2
).to('cuda:0') # 첫번째 모델을 cuda 0에 할당
self.seq2 = nn.Sequential(
self.layer3, self.layer4, self.avgpool,
).to('cuda:1') # 두번째 모델은 cuda 1에 할당
self.fc.to('cuda:1')
def forward(self, x):
x = self.seq2(self.seq1(x).to('cuda:1')) # 두 모델을 연결
return self.fc(x.view(x.size(0), -1))
Data parallel
데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법
minibatch 수식과 유사, 한번에 여러 GPU에서 수행
Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
- Pytorch에서는 아래 두 가지 방식을 제공
DataParallel: 단순히 데이터를 분배한 후 평균을 취함 → GPU 사용 불균형 문제 발생, Batch 사이즈 감소(한 GPU가 병목), GIL
parallel_model = torch.nn.DataParallel(model) predictions = parallel_model(inputs) loss = loss_function(predictions, lablels) loss.mean().backward() optimizer.step() predictions = parallel_model(inputs)DistributedDataParallel: 각 CPU마다 process 생성하여 개별 GPU에 할당 → 기본적으로 DataParallel로 하나 개별적으로 연산의 평균을 냄
train_sampler = torch.utils.data.distributed.DistiributedSampler(train_data) shuffle = False pin_memory = True trainloader = torch.utils.DataLoader(train_data, batch_size=20, shuffle=True, pin_memory=pin_memory, num_workers=3, shuffle=shuffle, sampler = train_sampler)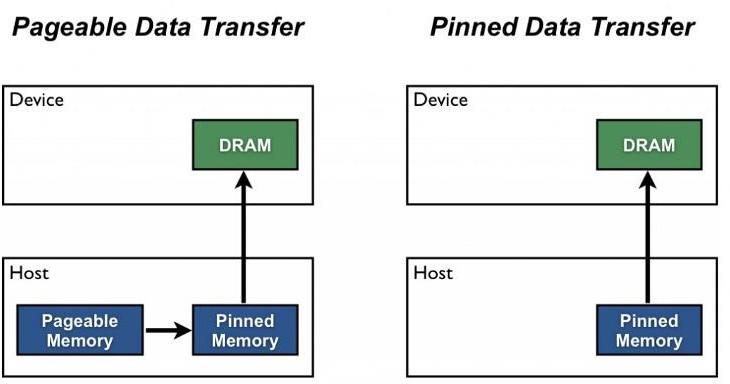
def main(): n_gpus = torch.cuda.device_count() torch.multiprocessing.spawn(main_worker, nprocs=n_gpus, args=(n_gpus, )) def main_worker(gpu, n_gpus): image_size = 224 batch_size = 512 num_worker = 8 epochs = ... batch_size = int(batch_size / n_gpus) num_worker = int(num_worker / n_gpus) # 멀티프로세싱 통신 규약 정의 torch.distributed.init_process_group( backend='nccl’, init_method='tcp://127.0.0.1:2568’, world_size=n_gpus, rank=gpu) # Distributed DataParallel 정의 model = MODEL torch.cuda.set_device(gpu) model = model.cuda(gpu) model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu]) # Python의 멀티프로세싱 코드 from multiprocessing import Pool def f(x): return x*x if __name__ == '__main ': with Pool(5) as p: print(p.map(f, [1, 2, 3]))
Hyperparameter Tuning
grid vs random, 최근에는 베이지안 기법들이 주도
Ray
- multi-node multi processing 지원 모듈
- ML/DL의 병렬 처리를 위해 개발된 모듈
- 기본적으로 현재 분산병렬 ML/DL 모듈의 표준
- Hyperparameter Search를 위한 다양한 모듈 제공
data_dir = os.path.abspath("./data")
load_data(data_dir)
# config에 search space 지정, 학습 스케줄링 알고리즘 지정
config = {
"l1": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"l2": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"lr": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16])
}
scheduler = ASHAScheduler(
metric="loss", mode="min", max_t=max_num_epochs, grace_period=1, reduction_factor=2)
# 결과 출력 양식 지정
reporter = CLIReporter(
metric_columns=["loss", "accuracy", "training_iteration"])
# 병렬 처리 양식으로 학습 시행
result = tune.run(
partial(train_cifar, data_dir=data_dir),
resources_per_trial={"cpu": 2, "gpu": gpus_per_trial},
config=config, num_samples=num_samples,
scheduler=scheduler,
progress_reporter=reporter)
PyTorch Troubleshooting
OOM(Out Of Memory)
- 왜 발생했는지 어려움, 어디서인지 어려움, Error backtracking이 이상한데로 감, 메모리 이전 상황의 파악 어려움
GPUUtil 사용하기
- nvidia-smi처럼 GPU 상태를 보여줌
- colab은 환경에서 GPU 상태 보여주기 편함
- iter마다 메모리가 늘어나는지 확인
!pip install GPUtil
import GPUtil
GPUtil.showUtilization()
torch.cuda.empty_cache()써보기
- 사용되지않은 GPU상 cache를 정리
- 가용 메모리를 확보
- del과는 구분이 필요
- reset 대신 쓰기 좋은 함수
import torch
from GPUtil import showUtilization as gpu_usage
print("Initial GPU Usage")
gpu_usage()
tensorList = []
for x in range(10):
tensorList.append(torch.randn(10000000,10).cuda())
print("GPU Usage after allcoating a bunch of Tensors")
gpu_usage()
del tensorList
print("GPU Usage after deleting the Tensors")
gpu_usage()
print("GPU Usage after emptying the cache")
torch.cuda.empty_cache()
gpu_usage()
trainingloop에 tensor로 축적되는 변수는 확인할것
- tensor로 처리된 변수는 GPU 상에 메모리 사용
- 해당 변수 loop 안에 연산에 있을 때 GPU에 computational graph를 생성(메모리 잠식)
total_loss = 0
for i in range(10000):
optimizer.zero_grad()
output = model(input)
loss = criterion(output)
loss.backward()
optimizer.step()
total_loss += loss
1-d tensor의 경우 python 기본객체로 변환하여 처리할 것
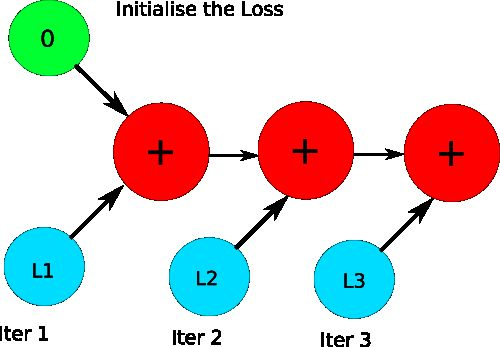
total_loss = 0
for x in range(10):
# assume loss is computed
iter_loss = torch.randn(3,4).mean()
iter_loss.requires_grad = True
total_loss += iter_loss
del 명령어를 적절히 사용하기
- 필요가 없어진 변수는 적절한 삭제가 필요
- python의 메모리 배치 특성상 loop이 끝나도 메모리를 차지함
가능한 batch 사이즈 실험
- 학습시 OOM이 발생했다면 batch 사이즈를 1로 해서 실험해보기
torch.no_grad() 사용하기
- inference 시점에서는 torch.no_grad() 구문을 사용
- backward pass로 인해 쌓이는 메모리에서 자유로움
with torch.no_grad():
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
예상치 못한 에러 메시지
- OOM 말고도 유사한 에러들이 발생
- CUDNN_STATUS_NOT_INIT 이나 device-side-assert 등
- 해당 에러도 cuda와 관련하여 OOM의 일종으로 생각될 수 있으며, 적절한 코드 처리의 필요함
그외…
- colab에서 너무 큰사이즈는 실행하지말 것 (linear,CNN,LSTM)
- CNN의 대부분의 에러는 크기가 안맞아서 생기는경우 (torchsummary등으로 사이즈를 맞출것)
- tensor의 float precision을 16bit로 줄일수도있음
