DL| You Only Look Once(YOLO)
You Only Look Once(YOLO)
YOLO 버전 - Yolo v1부터 Yolo v8까지 Yolo V5 - Deep learning YOLO-World: Real-Time Open-Vocabulary Object Detection BoostCampAITECH
특징
- 단일 신경망 구조를 사용하기 때문에 구성이 간단하며 빠름
- 주변 정보까지 학습하므로 이미지 전체를 처리하기 때문에 background error가 낮음
- input file을 받으면 하나의 convolution network가 이미지 내에서 찾고자 하는 객체의 bounding box의 위치 정보인 x, y, w, h와 해당 bounding box의 class 확률을 동시에 계산(위치 회귀와 클래스 분류를 하나의 네트워크에서 end-to-end로 처리하는 구조)
Yolov1 Pipeline
- confidence: Pr(Object)*IOU(intersection over unition)로 객체가 있을 확률과 예측 박스와 실제 박스의 겹침 정도를 곱한 값
- IOU(Intersection over Union): 정답 box와 예측 box의 교집합/ 합집합 크기
- 입력 이미지를 SxS 그리드로 나누기(S=7)
- 각 그리드 영역마다 B개의 Bounding box와 Confidence score 계산(B=2)
- 신뢰도(confidence) = Pr(Object) * IOU(truth pred)
- 각 셀마다 C개의 class에 대한 해당 클래스일 확률 계산(C=2)
class probability = Pr(Class_i Object)
더 자세하게
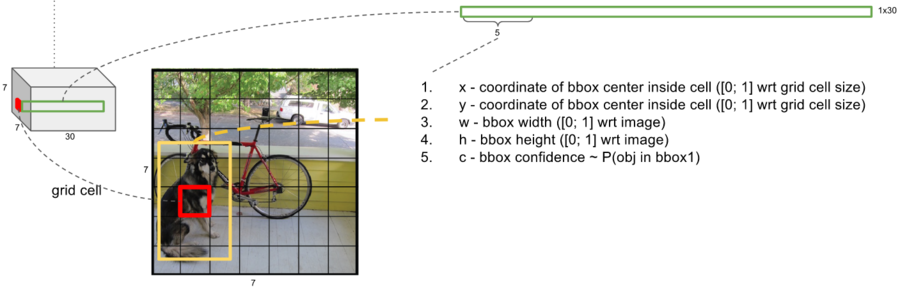
- 빨간색 박스: 7x7 중 하나의 그리드 셀
- 노란색 박스: 해당 셀이 예측한 bounding box
- x, y: 그리드 셀 내부 기준 중심 좌표
- w, h: 전체 이미지 기준 상대적 너비와 높이
- c: bbox confidence ~ P(obj in bbox)
bb1, bb2마다 x, y, w, h, c 5개, + C개의 클래스 확률 (Pr(Class_i Object)) = 총 30개
Class Score 계산
- bb1: confidence class x class probability
- bb2: confidence class x class probability
- 총 7×7 = 49개 셀 × 2개 박스 = 98개의 예측 bounding box
후처리
- Thresholding: 신뢰도 낮은 박스 제거
- 정렬: 높은 score 순으로 렬렬
- NMS (Non-Maximum Suppression): 가장 높은 score를 가진 박스를 선택
- 가장 높은 score의 박스를 선택
- 이와 IOU > 임계값인 다른 박스는 score를 0으로 설정 (제거)
- 최종적으로 남은 박스들: 의미 있는 박스들만 남고, 나머지는 score가 0이 되어 무시됨
Loss

Localilzation Loss
- 바운딩 박스의 중심 좌표 (x, y) 예측 오차
- 바운딩 박스의 width, height 예측 오차
왜 sqrt일까?: 넓은 박스와 좁은 박스의 오차를 비슷하게 고려하기 위해서
Confidence Loss
- 객체가 있는 경우에 대해 confidence score(IOU 값) 학습
- 객체가 없는 셀에 대해서도 confidence를 낮게 예측해야 함
Classficiaiton Loss
해당 셀에 객체가 있을 때 클래스 예측 확률을 학습 softmax 후의 class 확률과 ground truth class 간의 MSE
장단점
장점
- Faster R-CNN에 비해 6배 빠른 속도
- 다른 real-time detector에 비해 2배 높은 정확도
- 이미지 전체를 보기에 클래스와 사진에 대한 맥락적 정보를 가짐
- 물체의 일반화되니 표현을 학습
- 사용된 dataset외 새로운 도메인에 대한 이미지에 좋은 성능을 보임
단점
- 7*7 그리드 영역으로 나눠서 bounding box prediction 진행하므로 그리드보다 작은 크기의 물체 검출 불가능
- 신경망을 통과하여 마지막 feature만 사용하기에 정확도 하락
YOLO 종류
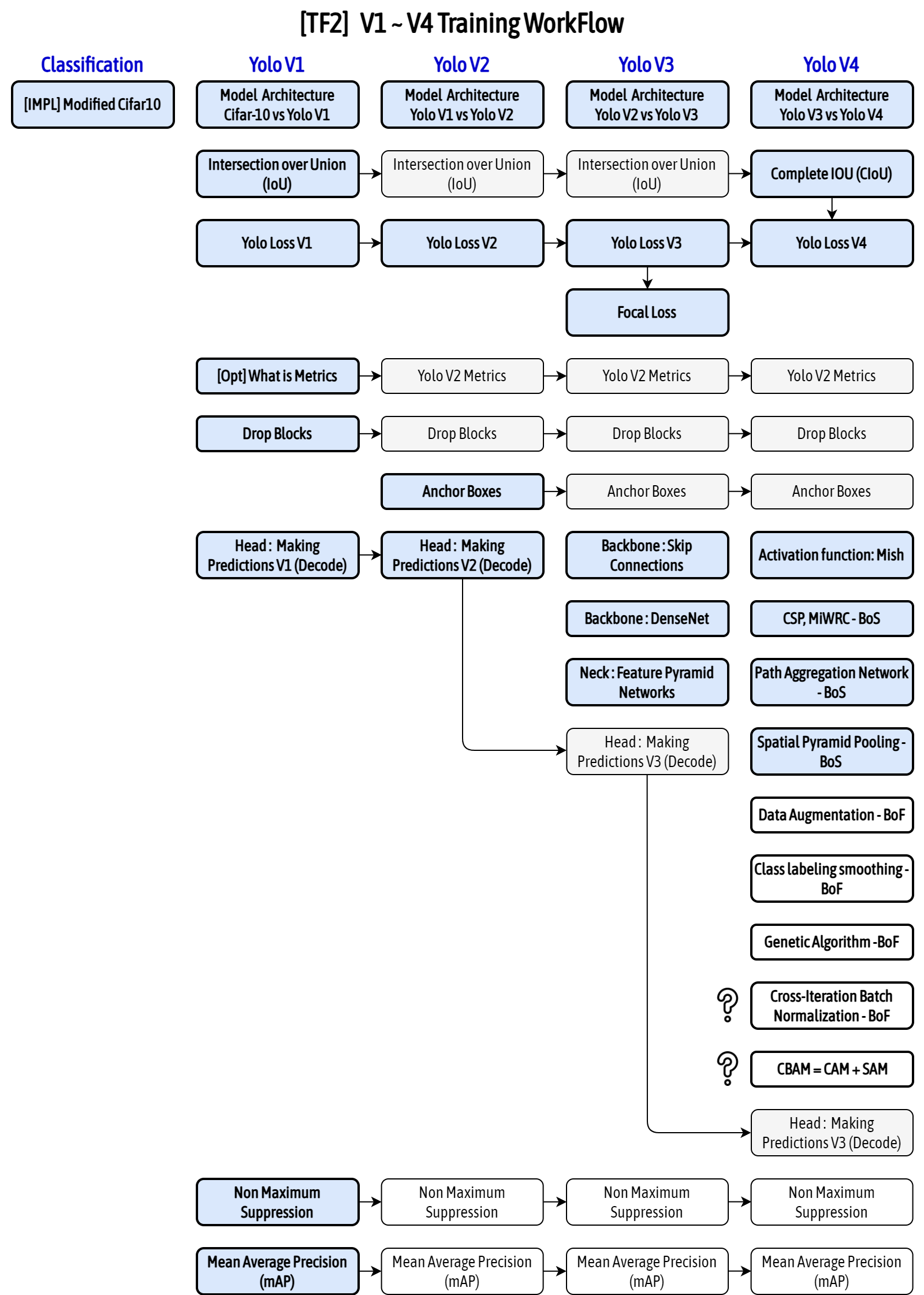
- YOLO v1: 하나의 이미지의 Bbox와 classification 동시에 예측하는 1 stage detector 등장
- YOLO v2: 빠르고 강력하고 더 좋게(3가지 방법)
- YOLO v3: multi-scale feature maps 사용
- YOLO v4: 최신 딥러닝 기술 사용(BOF, BOS)
- YOLO v5: 크기별로 모델 구성(Small, Medium, Large, Xlarge)
Yolov2
3가지 파트에서 모델을 향상
- Better: 정확도 향상
- Faster: 속도 향상
- Stronger: 더 많은 클래스 예측(80->9000)
Better
- Batch normlization: mAP 2% 향상
- High resolution classifier
- YOLOv1: 224x224 이미지로 사전 학습된 VGG를 448x448 Detection 테스크에 적용
- YOLOv2: 448x448 이미지로 새롭게 finetuning
- mAP 4% 향상
- Convolution with anchor boxes
- Fully connected layer 제거
- YOLO v1: grid cell의 bounding box의 좌표 값 랜덤으로 초기화 후 학습
- YOLO v2: anchor box 도입
- K means cluster on COCO datasets
- 5개의 anchor box
- 좌표 값 대신 offset 예측하는 문제가 단순하고 학습하기 쉬움
- mAP 5% 향상
- Fine-grained features
- 크기가 작은 feature map은 low level 정보가 부족
- Early feature map은 작은 low level 정보 함축
- Early feature map을 late feature map에 합쳐주는 passthrough layer 도입
- 26x26 feature map을 분할 후 결합
- Multi-scale traning
- 다양한 입력 이미지 사용
- multi-scale feature map과는 다름
Faster
- Backbone을 GoogLeNet에서 Darknet-19로 변경
- Darknet-19
- 마지막 fully connected layer 제거
- 대신 3x3 convolution layer로 대체
- 1x1 convlution layer 추가(채널수 125(5x(5+20)))
- Darknet-19
Stronger
- ImageNet(classficiation), Coco(detection)와 함께 사용
- Detection 데이터셋: 일반적인 객체 클래스로 분류(개, 고양이)
- 세부적인 객치 클래스로 분류 (개의 종류)
- WordTree 구성(계층적인 트리)
- ex “요크셔테리어” = 물리적객체(최상위 노드) - 동물 - 포유류 - 사냥개 - 테리어(최하위 노드)
- 총 9418 범주
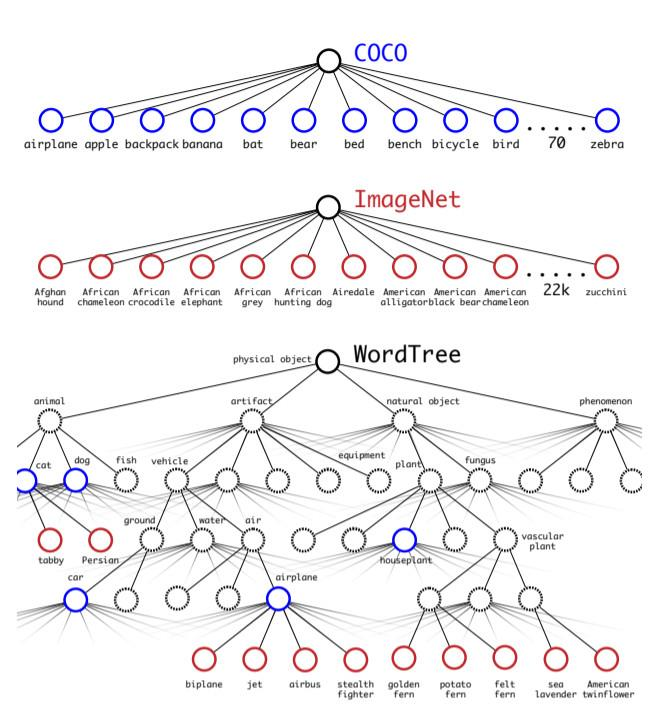
- ImageNet:COCO = 4:1
- Detection 이미지: clasficiation loss는 특정범주에 대해서만 loss 계산(개면 물리적객체-동물-포유류-개에 대해서만 loss 계산)
- Classficiation 이미지: classificaiton loss만 역전파 수행(IoU)
Yolov3
Darknet-53
- Skip connection 적용
- Max pooling x, convolution stride 2 사용
- ResNet-101, ResNet-152와 비슷한 성능, FPS 높음
Multi-scale Feature maps
- 서로 다른 3개의 sclae 사용
- Feature pyramid network 사용
- High-level의 fine-grained 정보와 low-level의 semantic 정보를 얻음
Yolov4
기존 YOLO 시리즈의 작은 객체 검출 문제를 해결하고자 했음
yolov4 = yolov3 + SCPDarknet53 + SPP + PAN + BoF + BoS
- input 해상도를 크게 사용 기존에는 224, 256 -> 512
- receptive filed를 물리적으로 키워주기 위해서 layer 수를 늘렸고, 하나의 image에서 다양한 종류, 다양한 크기의 object들을 동시에 검출하려면 높은 표현력이 필요하므로 parameter 수를 키움
- 정확도를 높이는 대신 생기는 속도 저하 문제는 아키텍처 변경으로 해결: FPN과 PAN을 도입해 멀티스케일 객체 탐지 성능을 향상시키고, CSP 기반의 경량화된 백본과 SPP 등의 효율적인 네트워크 구조를 적용해 정확도와 속도 모두 개선함.
FPN(Feature Pyramid Networks for Object Detection)
- 위에서 아래로(top-down) 피처 전달
- 상위 레벨의 추상적인 특징을 업샘플링해서 하위 레벨의 피처랑 결합
- 작은 객체 인식에 유리
- 주 목적: 고수준 정보를 저해상도 feature map에 전달
PAN(Path Aggregation Network)
- FPN에 추가적으로 아래에서 위로 경로를 더한 구조
- 하위 레벨의 세밀한 정보도 상위 레벨로 전달
- 피처 간의 정보 흐름을 양방향으로 만들어서 인식 성능을 높임
- 주목적: 저수준 정보를 고해상도 feature map에 전달
BoF(Bag of Freebies)
BoF는 inference 시간을 늘리지 않으면서 더 높은 정확도를 얻기 위해 학습시키는 방법
BoS(Bag of Specials)
inference 시간을 조금 증가시키지만, 정확도는 크게 향상시키는 방법
SPP(Spatial Pyramid Pooling)
backbone에서 얻은 feature map에 대한 receptive filed를 키우는 방법 중 하나로 feature map을 정해준 grid에 맞추어 max pooling을 진행
Yolov5
yolov4와 같은 CSPNet 기반의 backbone을 Pytorch로 구현하여 C언어 기반은 Darknet이 아닌 pytorch로 구현하였기에 이전 버전과 다르다고 볼 수 있음
4가지 모델로 소개가 되었는데 backbone을 depth multiple과 width multiple을 기준으로 나눔(s, m, l, x)
- s: 제일 가벼운 모델(성능이 낮음, 프레임 수 높음)
- x: 제일 무거운 모델(성능이 좋음, 프레임 수 낮음)
Head에 Neck 부분이 같이 존재하며, 마지막 Detect Layer가 Head를 담당
YoloV5의 아키텍쳐는 최대한 일반적인 환경에서 최소한의 라벨링으로 detection을 할수 있게 설계됨
YOLO World
시각 정보와 언어 정보 간의 상호 작용을 촉진하기 위해 새로운 RepVL-PAN이라는 네트워크를 사용, 제로샷 방식으로 효율적으로 탐지가 가능하도록 동작하며 높은 FPS로 기존 발표된 비전-언어 모델과 비교해 약 20개량 빠름
구조
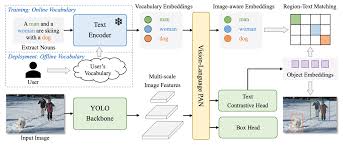
- RepVL-PAN 제안: 이미지 특징과 텍스트 임베딩을 융합하여 시각적-의미적 표현을 향상
- Region-Text Contrastive Loss: 이미지 내의 영역과 텍스트 간의 대비 학습을 통해 YOLO-Wolrd가 다양한 객체를 zero-shot 방식으로 검출할 수 있도록 함
- Prompt-then-Detect 패러다미 제시: 효율적인 추론을 위해 사용자가 프롬프트를 미리 인코딩하여 오프라인 어휘를 구축하고, 모델에 통합하는 방식 제안
etc..
원작자는 v3에 개발 중단, 계속 나오는 것들은 개발하는 팀이 다 다름
