DL| Monocular Depth Estimation, Depth Anything
in Blog / DL on Monocular depth estimation, Depth anything
Monocular Depth Estimation
20190416 Monocular Depth Estimation Junho Choi Deep Learning 기반 Depth Estimation with Mono Camera Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data Depth Estimation의 평가 지표 Monocular Depth Estimation using ZoeDepth : Our Experience
- Mono depth estimation
- Open Dataset
- Supervised Learning에서의 첫 논문: Multi-scale deep network[Eigen at al. 2014]
- UnSupervised Learning: UnSupervised Monocular depth estimation[Godard et al. 2017]
- High Quality Monocular Depth Estimation via Transfoer Learning[Alhansim et al. 2018]
- MonoDepth
- Depth Anything
Mono depth estimation
컴퓨터 비전 분야에서 depth가 포함된 Stereo camera를 사용하지 않고 일반 단일 카메라의 이미지로부터 깊이 정보를 추정하는 작업
Depth Estimation 원리
- Triangulation 방식을 사용하여 모노카메라에서 이전 타임스탬프의 이미지와 현재 타임 스탬프의 이미지 쌍을 활용하여 깊이를 추정
- 해당 방식에서 동일한 실제 환경의 좌표인 3D 포인트가 두 개의 이미지에 투영이 되어 이미지 상의 한 쌍의 2D 좌표(u, v)를 구성
- 이 때, 이동한 카메라의 포즈 또는 두 카메라 사이의 포즈를 알 수 있다면 모노카메라에서 두 이미지 간의 관계를 설명할 수 있는 Fundamental Matrix와 한 이미지 상의 특정 점에 대응하는 다른 이미지 상의 점간의 관계를 파악할 수 있는 epipolar geometry를 이용하여 3D 공간 좌표를 추정 가능
관련 연구 동향
- 대표적인 딥러닝 알고리즘으로는 Monodepth, DenseDepth, FastDepth
- 최근 Transformer, self-supervised learning 등 복잡한 모델과 결합
Statistical Model
- Graph and Super-pixel based image segmentation
- 통계학적 정보를 배경으로 feature vector 추정
- segmentation을 하고 가까운 영역이 depth 가 가깝고, farthermost position이 depth가 멈
Supervised Learning
- pixel-wise regression
- depth prediction, ground truth를 픽셀별로 비교해서 최솟값을 찾는 것을 학습
Open Dataset
- NYU Depth Dataset: Microsoft Kinect, Indoor enviornment
- KITTI: Velodyne laser scanner, Outdoor enviornment
Supervised Learning에서의 첫 논문: Multi-scale deep network[Eigen at al. 2014]
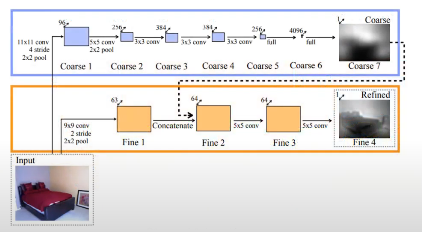

- Multi-scale deep network
- Global coarse-scale: vanishing points, object locations를 추정
- Local fine-scale network: details such as object and walls
- Scale-Invariant Error
- depth map이 절대적인 값들이 중요(상대적인 값들을 비교해서 scaling된 에러를 매기는)
- 상대적인 depth map을 매기는데 유용

- supervised learning의 단점: gt에 의존, opendata의 신뢰성…에 대한 문제(움직이는 object depth error가 발생하고 ground truths 에러), LiDAR 스캐너 노이즈
→ UnSupervised Learning
UnSupervised Learning: UnSupervised Monocular depth estimation[Godard et al. 2017]
- stereo 카메라 2개
Left-right consistency - Disparity
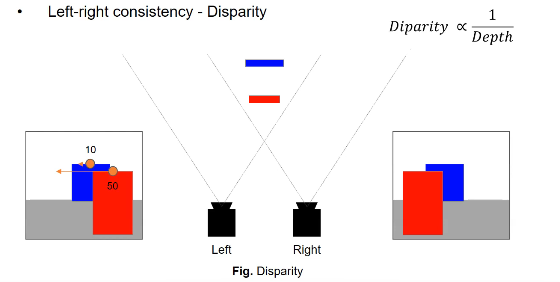
- 가까이 있는 것은 적게 움직이고, 멀리 있는 것은 많이 움직이는 것을 토대로 depth 추정
Sampler from STN(Spatial Transformer Networks)
- 회전을 해도 인식하는 것을 CNN에서는 max pooling이 역할해줌
- STN은 특정 부분을 자르고 변환해서 train하기 때문에 좀 더 효율적
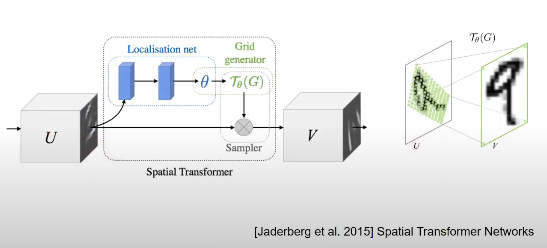
- Loclisation net: 입력 이미지 U에 어떤 geometric transformation(변환)을 적용해야 하는지를 예측하는 네트워크 -> Transformation matrix 출력
- Grid generator: 이미지에서 어떤 부분을 잘라내서 transformation matrix를 반영할지 결정해줌
- U가 살짝 틀렸다면 Sampler를 통해서 V로 변환해줌으로써 Transform 해줌
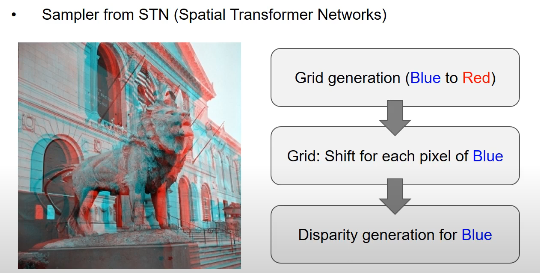
- Disparity의 오른쪽과 왼쪽을 Blue, Red라고 했을 때 Blue에서 Red로 바꾸기 위해서 Sampler를 사용
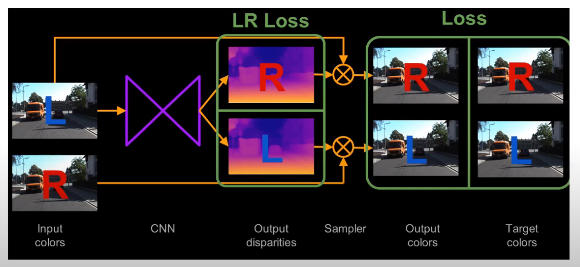
- sampler를 통해서 output 컬러랑 input 컬러랑 비교해서 최소화하는 Disparity랑 output 컬러를 만듬
- Disparity를 만들면 스테레오 카메라가 calibration 데이터라고 가정햇을 때 Disparity로 depth map을 생성
- 왼쪽이미지를 통해서 Disparity를 생성
- Disparity에서 샘플러를 통해서 R, L 이미지 생성
- 만들어진 R, L을 input에서의 R, L를 최소화하도록 네트워크 학습
- Apperance Matching Loss, Disparity Smoothness Loss, Left-Right Disparity Consistency Loss
High Quality Monocular Depth Estimation via Transfoer Learning[Alhansim et al. 2018]
- Encoder-decoder architecture
- Transfer learning for high-quality depth estimation
MonoDepth
그래서 일반적으로 Depth estimation은 Left image, Right image의 시차인 disparity를 구하고 Depth = (focal length * base line) / disparity를 통해 Depth를 구함
이를 딥러닝으로 해결할 수 있는 알고리즘이 Mono Depth
- Left image가 input으로 들어가서 CNN 통과하고 left disparity와 right disaprity를 얻음
- left disparity와 right disparty를 이용해 image reconstruction, left-right consistency등의 loss를 사용해 학습 진행
- 해당 논문에서 사용한 loss는 left-right disparity consistency loss와 Appearance Matching Loss, Disparity Smoothness Loss 가 있음
Depth Anything
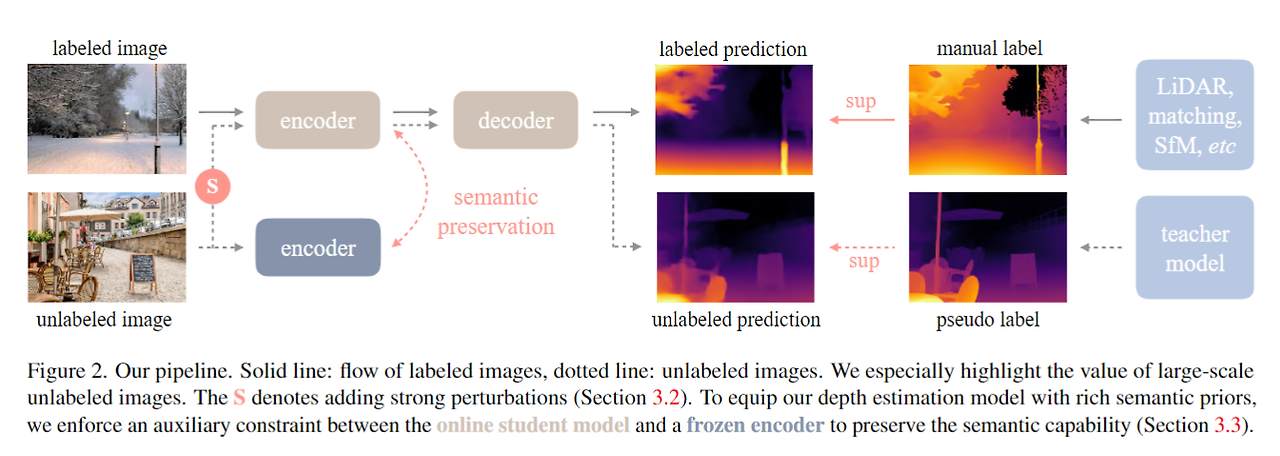
- 대규모 데이터 사용
- pseudo label
- 상대적 깊이 추정뿐만 아니라, NYUv2 및 KITTI와 같은 데이터셋을 활용한 절대 깊이 추정(metric depth estimation)에도 활용
Encoder: DINOv2, Decoder: DPT
- Depth Anything 모델은 상대 깊이 추정에 중점
- metric depth estimation을 위해 ZeoDepth를 따라 NYUv2 or KITTI의 메트릭 깊이 정보를 사용해서 사전 훈련된 Depth Anything encoder를 미세 조정
- Metric Depth Estimation (MDE): 물리적 단위로 깊이 값을 제공하는 작업이 포함됨
- Relative Depth Estimation (RDE): 객체가 서로 얼마나 가깝거나 멀리 떨어져있는지를 나타냄
- MDE가 유용한 정보를 제공하는 것 같지만 모델을 다양한 장면에서 일반화 하는 것은 매우 어려움… (RDE는 그런 문제점이 없음) → 실내, 실외 데이터 셋의 경우 깊이 값의 범위가 달라서 따로 학습하는 편
- ZoeDeep이 제안: RDE를 하고 MDE dataset을 finetuning하는 방식으로 RDE, MDE를 통합하는 것
- ZoeDepth가 MiDAS의 깊이 추정 프레임워크를 사용하고 새로운 head, train 방법을 추가
