DL| Transformer 구조
Transformer 구조 정리
Transformer The Illustrated Transformer BoostCampAITECH
Transformer
NLP에서 long range dependecy를 해결하였고 vision에도 적용하였음
Transformer 구조는 BERT, GPT 등의 구조 기반이 되었고 다양한 분야로의 접목이 활발히 연구되고 있는 매우 중요한 neural networks 구조 중 하나
이전에는 RNN(LSTM, GRU), Convolution 등으로 sequence 모델링을 수행했으나 Trnasformer는 recurrence, convolution의 개념을 아예 배제하고 순수하게 attention으로 구성되어 RNN, CNN 계열에 비해 속도와 성능이 우월
Overview

Transformer 모델에 들아가면 번역된 출력 문장이 나옴
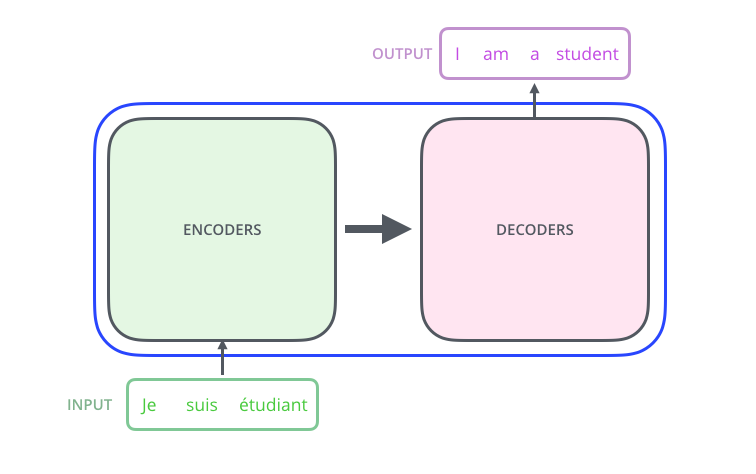
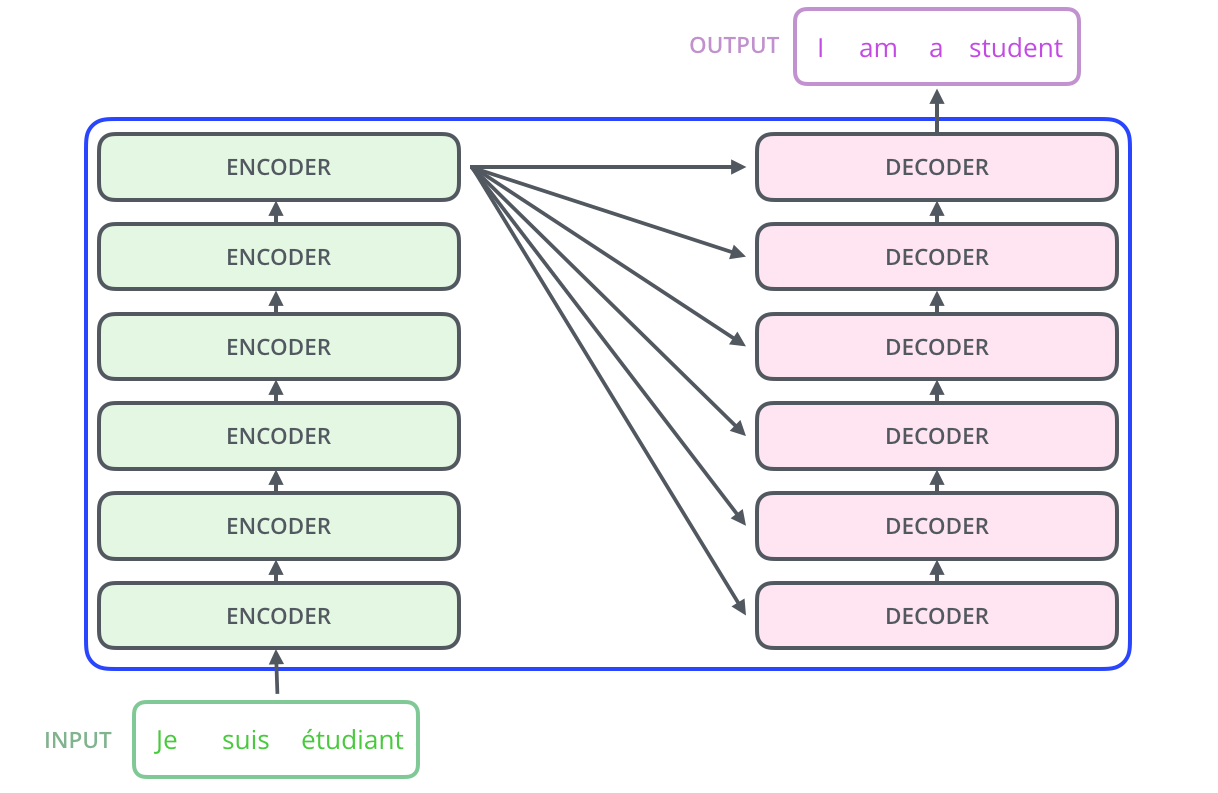
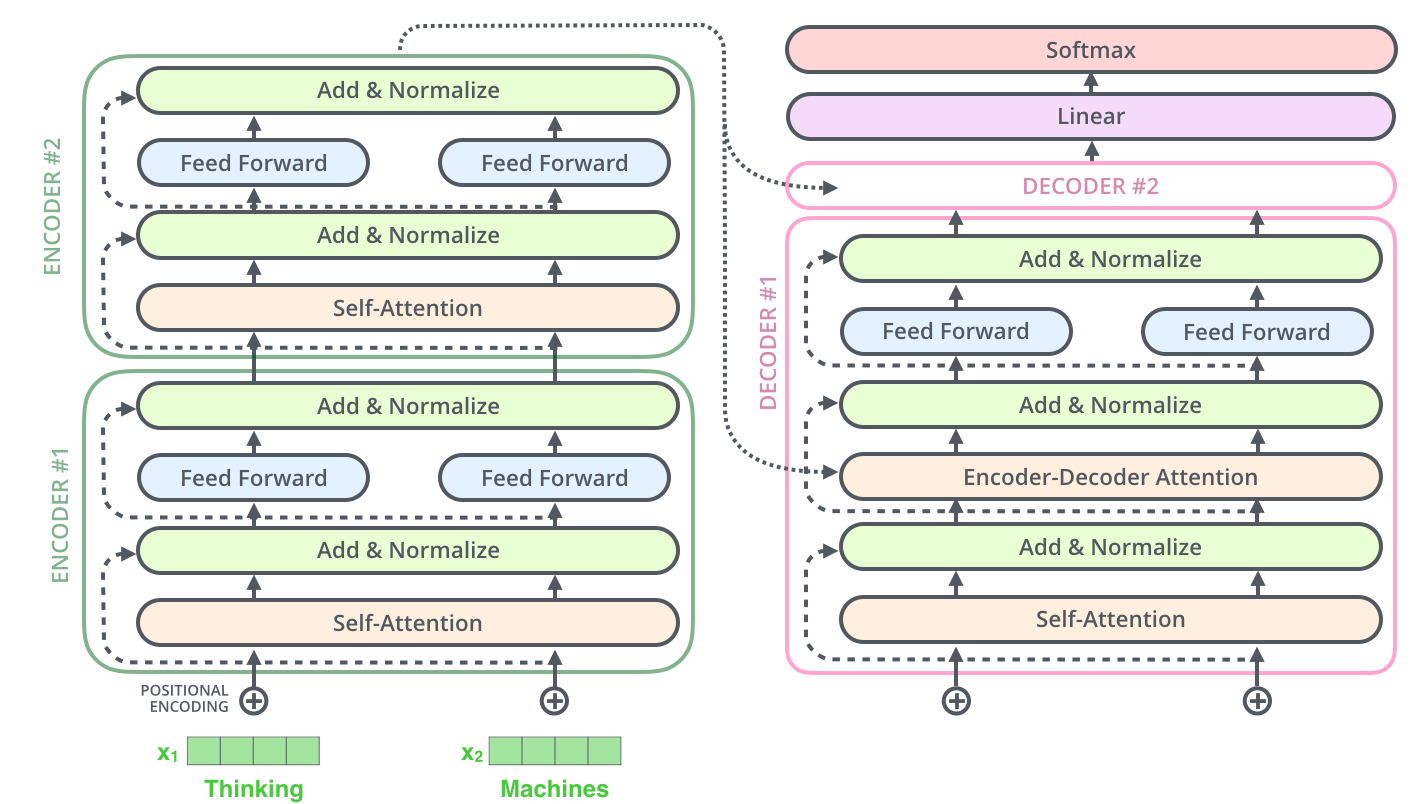
- black box로 되어있는 Transformer 구조를 열면 Encoder, Decoder 구성되어져 있음
- 인코딩 구성요소는 인코더를 여러개 쌓아 올린 것이고, 디코딩 구성 요소는 같은 번호의 디코더를 여러 개 쌓아 올린 것임
- 모든 인코더는 구조가 동일하지만 가중치는 공유하지 않음, 각 인코더는 두 개의 하위 계층으로 나뉨
Encoder, Decoder
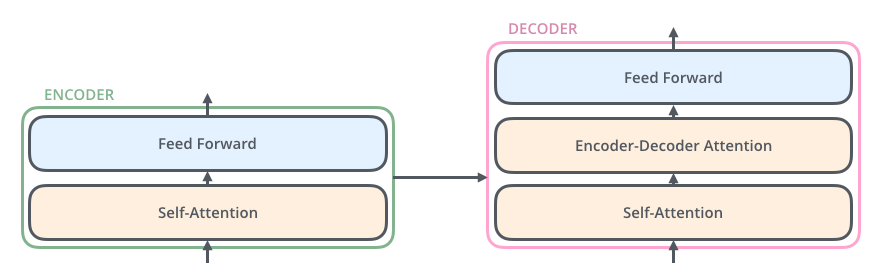
- 인코더의 입력은 self-attention을 통과하는데 이것의 출력은 feed forward 신경망에 입력됨(self attention는 인코더가 특정 단어를 인코딩할 때 입력 문장의 다른 단어를 살펴보는데 도움을 주는 계층임)
- 디코더는 두 계층을 모두 가지지만 두 계층 사이에 encoder-decoder attetnion(입력 문장의 관련 부분에 집중할 수 있도록 돕는 계층)이 있음
그림으로 살펴보기
훈련된 모델의 입력이 출력으로 변환되는 과정에서 각 벡터와 텐서가 어떻게 구성 요소 사이를 흐르는지
일반적인 NLP와 마찬가지로 임베딩 알고리즘을 사용하여 각 입력 단어를 벡터로 변환하는 것을 시작

- 각 단어 → 512차원 벡터로 임베딩됨 (가장 아래 인코더에서만 수행)
- 모든 인코더는 “512차원 벡터 리스트”를 입력으로 받음
- 아래 인코더는 단어 임베딩이 입력
- 위 인코더들은 바로 아래 인코더의 출력이 입력
- 리스트 길이 (= 단어 수)는 하이퍼파라미터로 고정
단어를 입력 시퀀스에 내장한 후, 각 단어는 인코더의 두 계층을 각각 통과
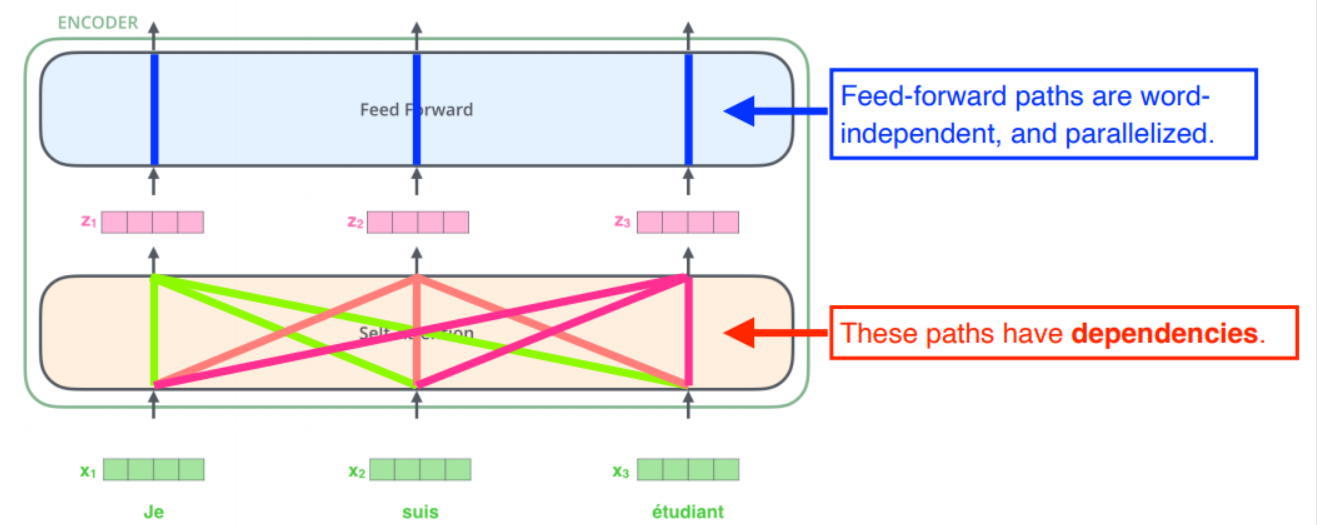
입력 시퀀스의 단어들을 임베딩하고 각 단어는 인코더의 두 레이어를 통과하는데
- self-attention: 의존성이 존재
- feed-forward: 의존성이 없어 병렬 처리
Encoding
encoder는 벡터 목록을 입력으로 받고, 이 벡터들을 self-attention 계층으로 전달한 후, feed-forward 신경망으로 전달하여 목록 처리 → 출력을 다음 인코더로 전송
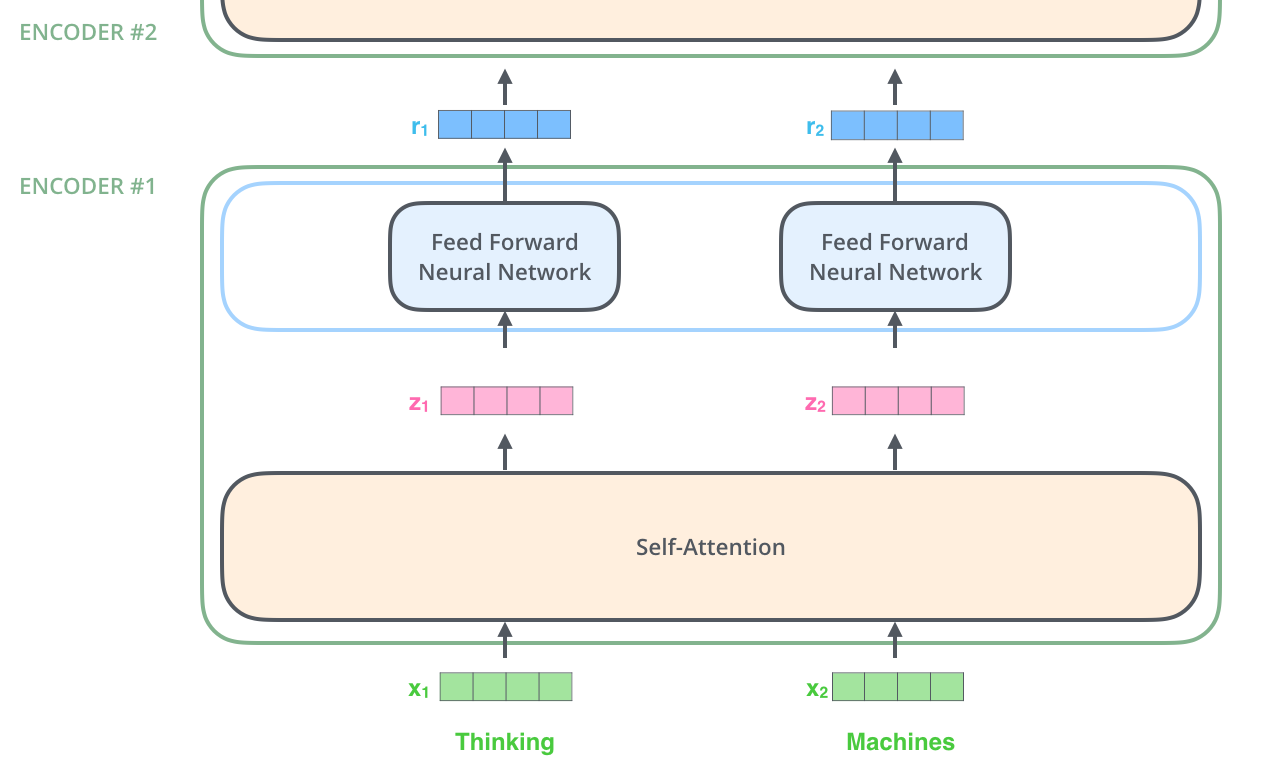
Self Attention
self라는 말처럼 자기 자신에 대해서 주목한다는 뜻으로 하나의 문장에 대해서 각 위치의 단어 별로 어느 위치의 단어와 연관이 있는지를 파악한다는 것
“The animal didn’t cross the street becuase it was too tired”에서 it이 animal을 나타내는 것을 self-attention을 통해서 연관있음을 알려주는 것으로 입력의 특정 위치에 대해서 다른 위치의 값들과 연관성을 파악하여 해당 위치에 대한 representation을 잘 추출하고자 하는 것이 목적
과정
- query, key, value의 벡터가 생성(임베딩 벡터보다 차원이 64로 작음, 임베딩 및 인코더 입출력 벡터는 512로 multi-head attention 계산을 일정하게 유지하기 위함, head가 8이므로 512d에서 나눠준 64사용)
- x1에 WQ 가중치 행렬을 곱하면 해당 단어와 관련된 query 벡터인 q1이 생성
- 입력 문장의 각 단어에 해서 query, key, value의 projection을 생성하게 됨
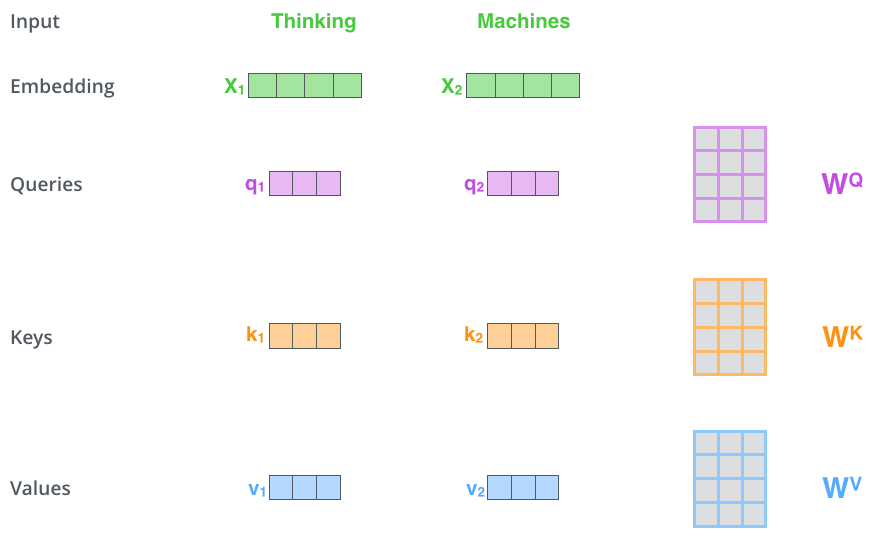
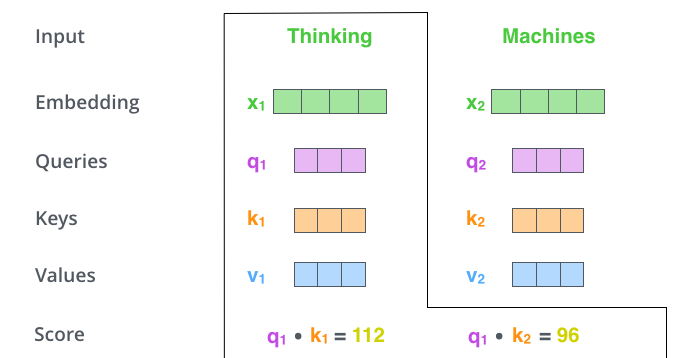
- query, key 벡터를 곱하여(dot product) attention socre 계산
- Thinking에 대한 self-attention을 계산한다면 query q1에 대해서 각 위치의 key 벡터를 곱해줌으로써 각 위치별 attention socre를 구함
이 score는 해당 위치의 단어가 다른 위치의 단어에 얼마나 집중할지를 나타냄
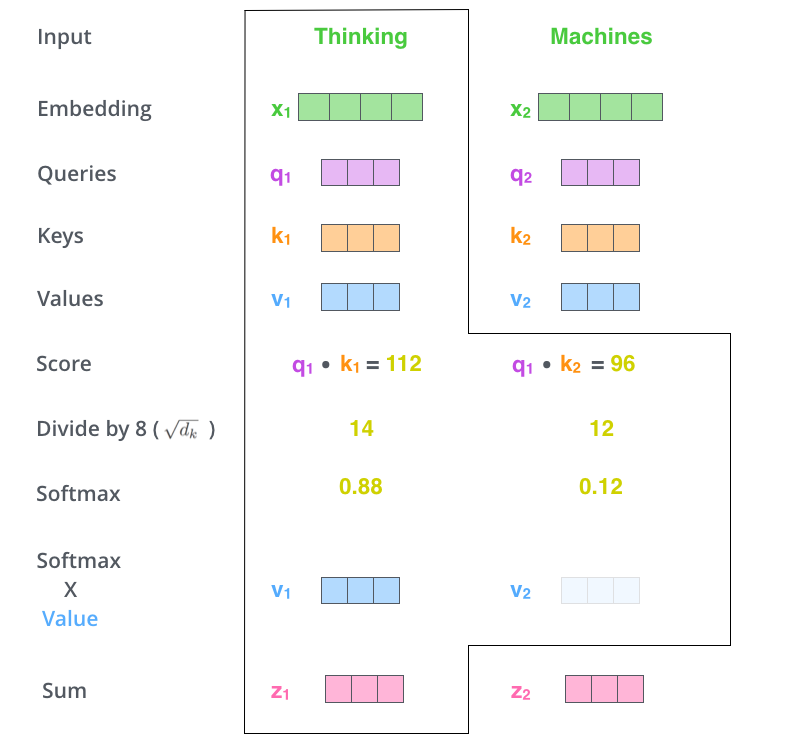
- attention score를 (8)로 나누고 softmax 함수를 취해 확률 형태로 변경
- 8: 논문에서 사용된 핵심 벡터 차원의 64의 제곱근
- softmax 연산은 정수를 모두 양수로 구하고 합이 1
- softmax score를 weight로 하여 각 위치의 value 벡터와 weighted sum 계산
- 집중하고자 하는 단어는 그대로 유지하고, 관련이 없다면 0.0001과 같은 작은 값을 곱하여 제외
- 최종적으로 마지막 z가 특정 위치에서의 self-attention score임
위의 그림은 한 위치의 벡터에 대해서 self-attetnion 연산을 수행한 것
입력 문장 전체에 대해서 행렬 형태로 나타내면 왼쪽의 Scaled Dot-Product Attention
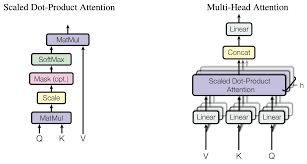
Self-Attetnion의 행렬 계산
임베딩을 행렬 X에 패킹하고, 이를 우리가 훈련시킨 가중치 행렬(WQ, WK, WV)과 곱하여 계산
X 행렬의 각 행은 입력 문장의 각 단어에 해당하고 임베딩 벡터의 크기(512, or 4 boxes in the figure), q/k/v/ 벡터(64, or 3 boxes in the figure)의 차이를 확인할 수 있음
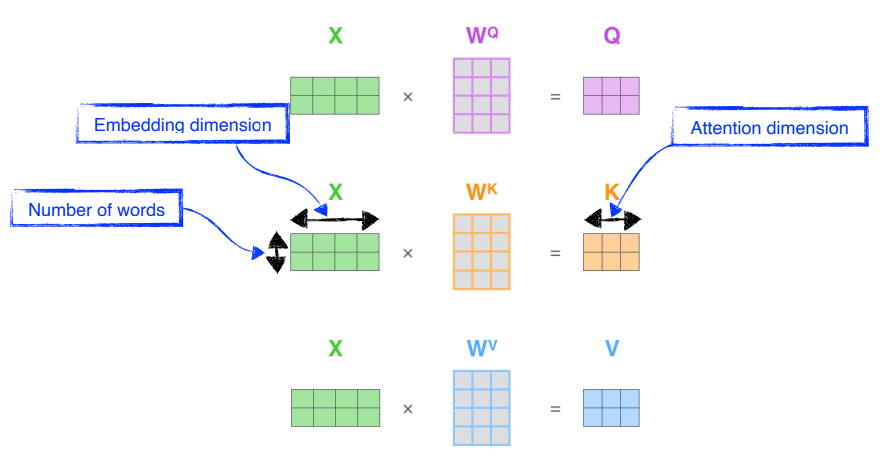
행렬을 다루고 있기에 위에서 진행했던 과정을 하나의 수식으로 압축하여 self-attetnion 레이어의 출력을 계산
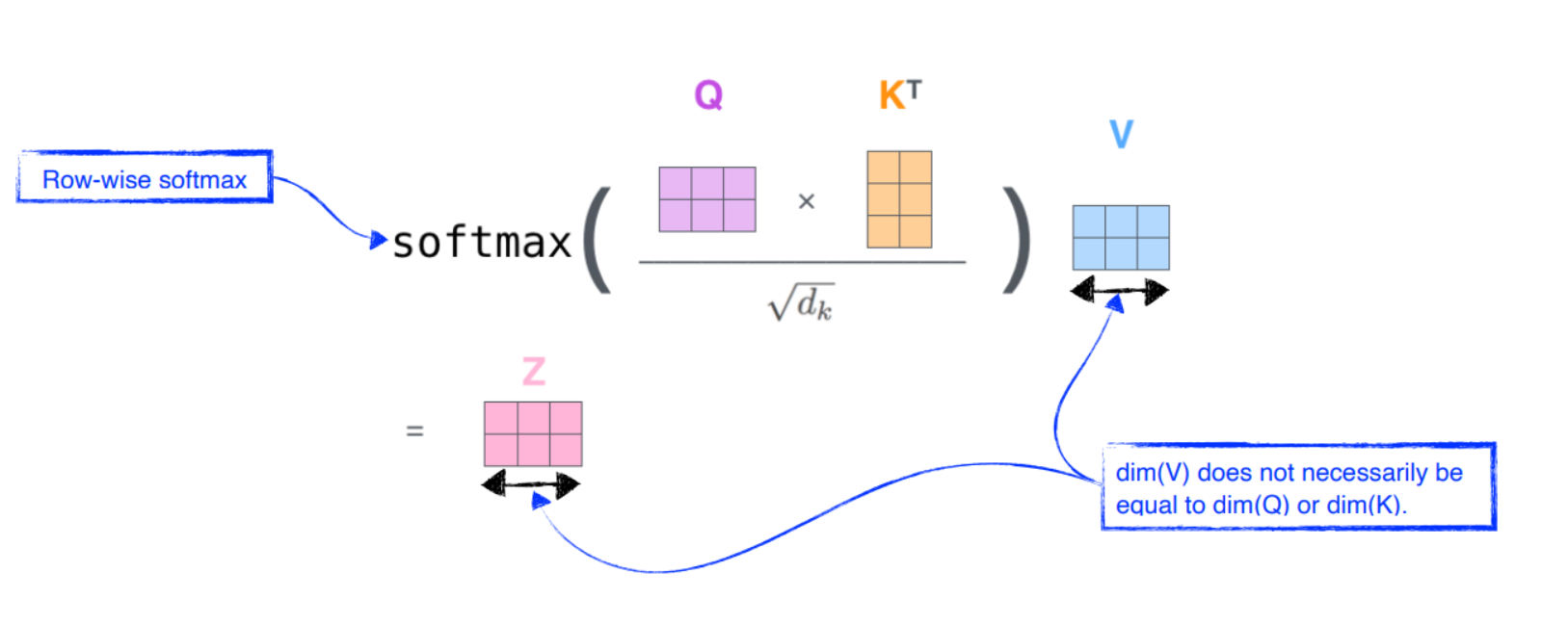
Multi-headed attention(MHA)
multi headed attention을 추가하여 더욱 개선, h=8 번 만큼의 attention을 독립적으로 수행

각 head 별로 가 존재하여 병렬적으로 attetnion을 수행, 각 head별로 추출된 벡터를 이어 붙이고(concat) 이를 에 곱한 값을 self attetnion sublayer의 최종 결과값으로 사용함
- 해당 시퀀스의 특정 위치에 대해 다른 위치에 대한 attention 능력을 향상
- attention layer에 여러 개의 representation subspace를 가질 수 있게 함
- q/k/v의 가중치 행렬이 여러 세트이고, 무작위로 초기화, 학습 후 입력 임베딩(또는 하위 인코더/디코더의 벡터)을 서로 다른 공간으로 투영하는데 사용
- q/k/v 행렬 셋이 여러개가 있고 각 셋은 무작위로 초기화, 학습 후에 각 셋은 입력 임베딩(또는 하위 인코더/디코더의 벡터)을 다른 표현 부분 공간에 투영하는데 사용
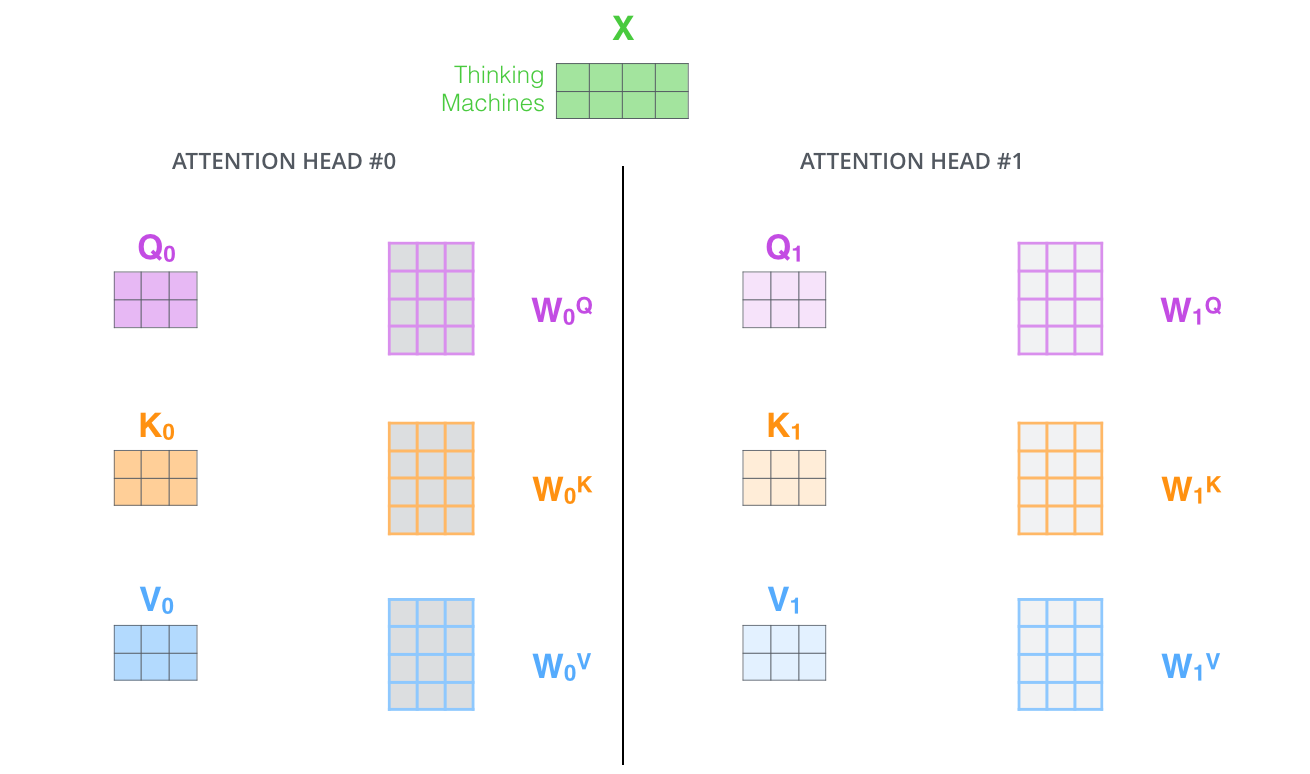
head 0의 z1이 자기 자신의 위치에만 지나치게 집중되면 고려하고 싶은 다른 위치와의 연관성을 모델링할 수 없으니 multi-head attetnion을 사용하여 모델이 각 위치별로 여러 개의 representataion subspace로부터 각기 다른 attention 정보를 추출해 종합할 수 있게 함
head 별로 attention score를 뽑으면 각기 다른 위치에 집중하는 양상을 보임

문제점
다른 가중치 행렬을 사용하면 8개의 다른 Z 행렬을 얻게 되는데 feed-forward 계층은 8개의 행렬이 아닌 단일 행렬을 원하므로 압축이 필요함
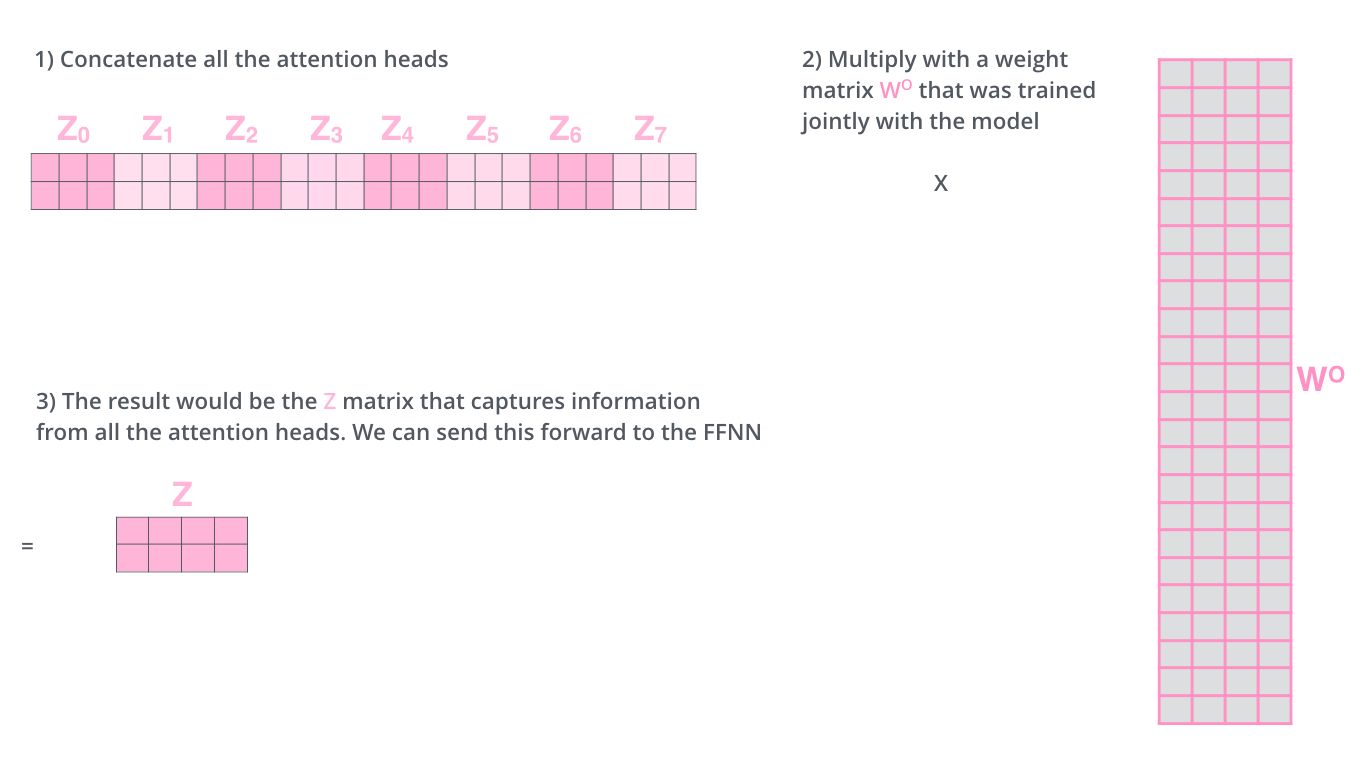
최종
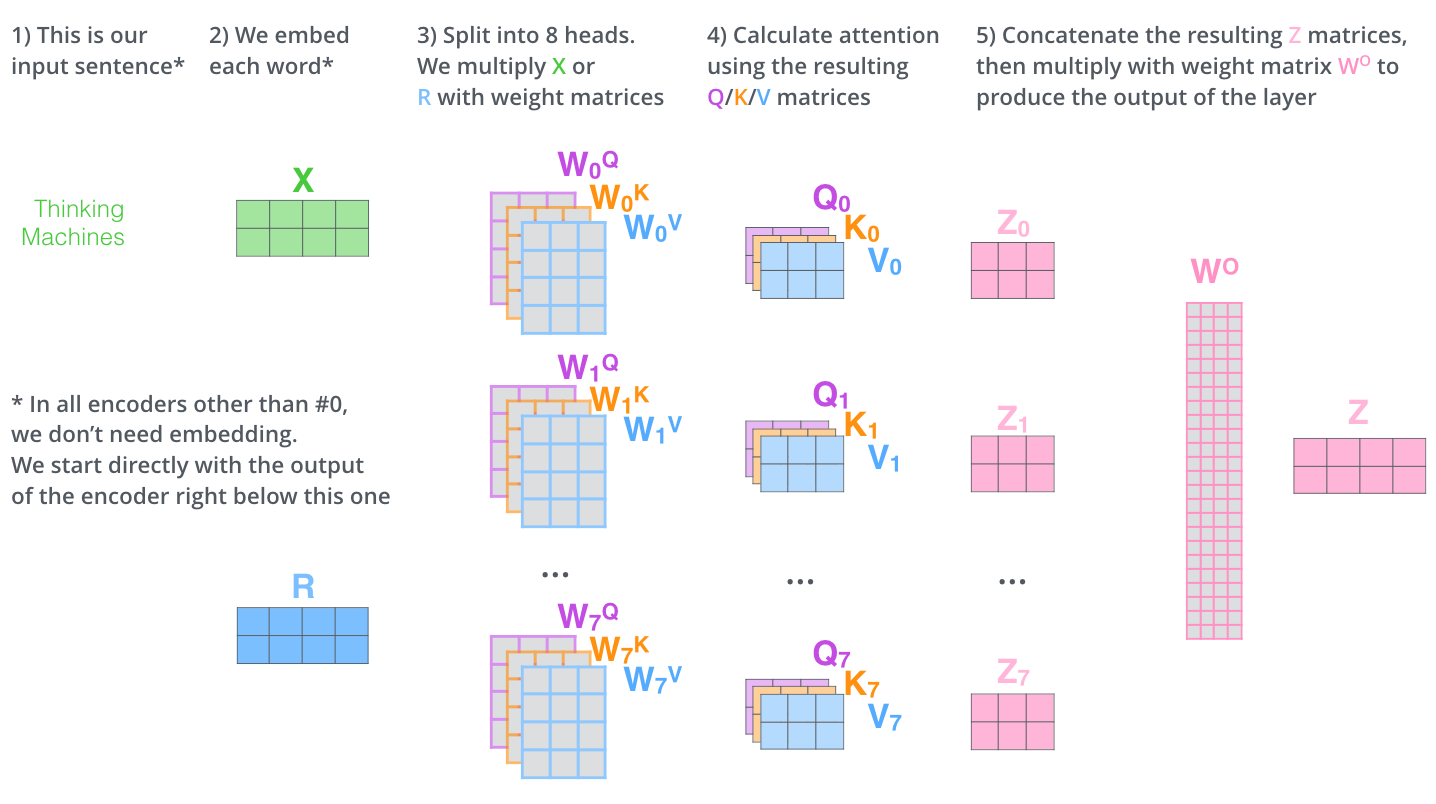
Applications of attetnion in Transformer
Transformer에서는 mluti-head attetnion을 3가지 구성요소에 사용
- Decoder의 encoder-decoder attetnion layer에 사용
- q는 직전 decoder layer로부터 받은 출력으로 사용
- k, v는 encoder의 출력으로 사용
- 이 과정으로 decoder의 각 위치가 입력 시퀀스의 모든 위치에 대해 attetnion을 수행
- Encoder의 self-attention layer에 사용
- q/k/v 모두 직전 encoder layer로부터 받은 출력이 계산되고 encoder의 각 위치가 입력 시퀀스의 모든 위치에 대해 attetnion수행
- 마찬가지로 Decoder의 self-attention layer에 사용
- 다만 decoder에서는 현재 입력은 미래가 아닌 과거로부터 영향을 받는다는 causality, auto-regressive를 유지하기 위해서 softmax 함수에 들어가기 전에 dot-product 수행 시 해당 위치에 대한 미래 부분을 -∞로 마스킹하여 해당 부분에 대해 attetnion이 수행되지 못하게 함
Other Details
전체적인 Transformer의 구조
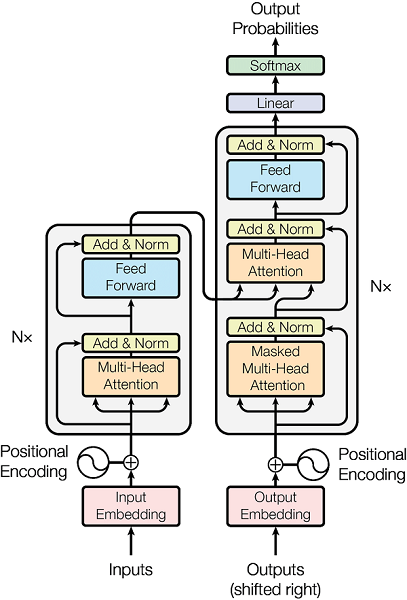
- 입력, 출력 시퀀스에 대해서 임베딩을 수행하고, encoder, decoder layer가 N=6 회만큼 동일하게 반복
- 특히 sublayer마다 residual connection, layer normlization 적용
각 sublayer의 최종 출력은 입력 x에 대해서
가 됨
Positional Encoding
위의 내용은 입력 시퀀스에서 단어들의 순서를 반영하는 방법이 빠져있는데, Trnasformer는 각 입력 임베딩에 위치 정보를 담은 벡터를 더함
이 벡터는 특정한 패턴을 따르며 모델이 이를 학습함으로써 각 단어의 위치나 시퀀스 내 다른 단어간의 거리를 파악할 수 있도록 도움(이러한 값을 임베딩에 더해 Q/K/V 벡터로 투영되고 dot-product attention이 적용될 때 의미있는 거리 정보를 제공함)
Positional encoding은 마찬가지로 d_model 차원의 벡터이고 Transformer에서는 sin, cos 함수를 사용

pos는 위치, i는 차원으로 짝수는 사인, 홀수는 코사인으로 positional encoding을 수행하고 2파이부터 100000*2파이까지 다양하게 존재함
이러한 함수를 사용한 이유는 본 적이 없는 긴 길이에 시퀀스에 대해서도 쉽게 positional encoding을 생성할 수 있기 떄문

임베딩의 차원이 4라면 실제 위치 인코딩은 다음과 같음
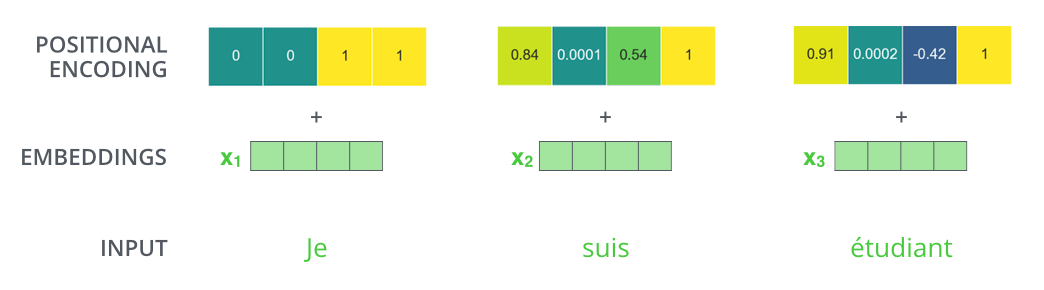
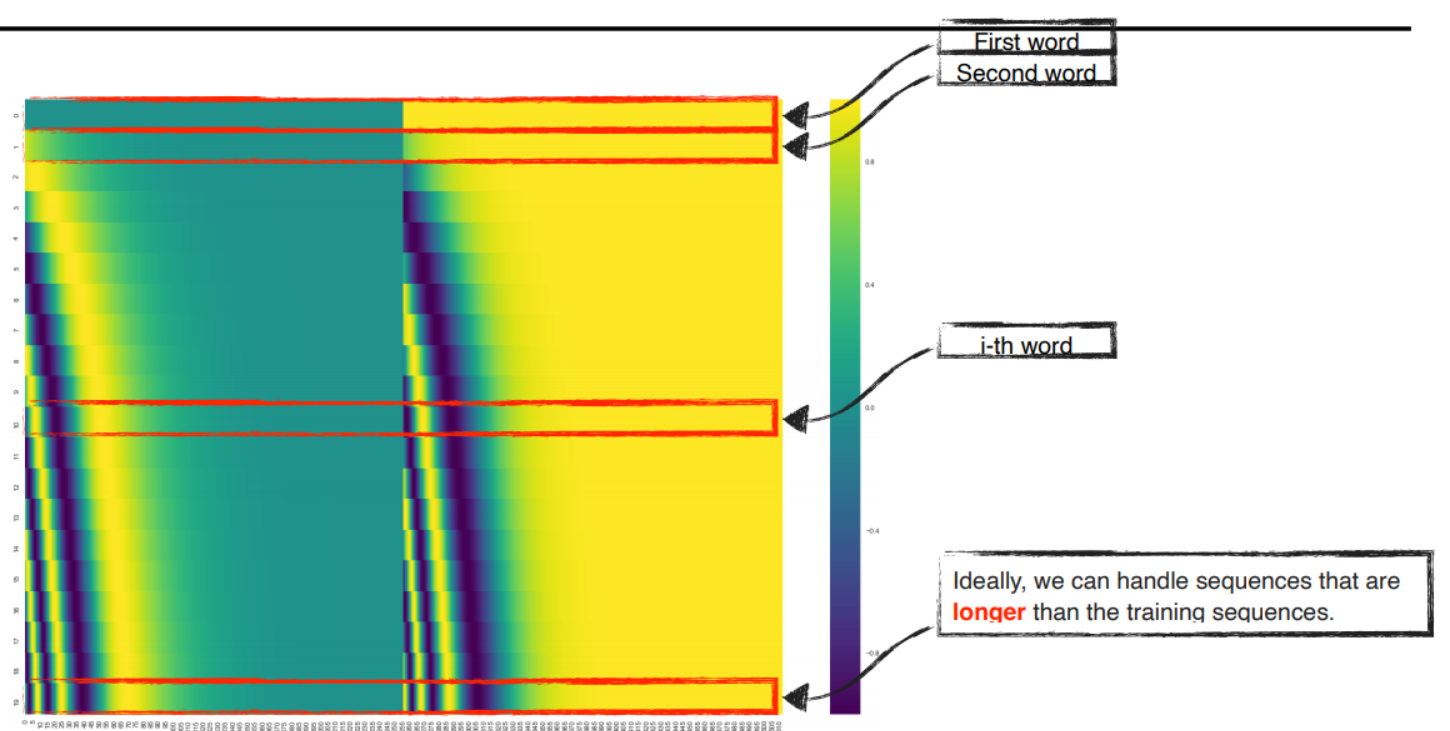
This is the case for 512-dimensional encoding, 왼쪽은 sine, 오른쪽은 cosine이고 concat하여 각 위치 인코딩 벡터 형성
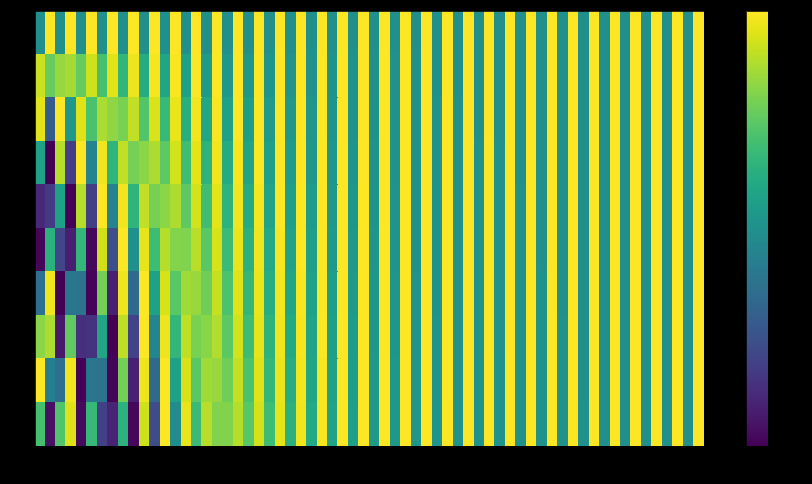
transformer의 tensor2tensor의 구현 → 두 신호를 직접 연결한 것이 아닌 interweaves
Feed Forward
- W1: 입력 차원 → 확장 차원
- W2: 확장 차원 → 입력 차원
- 비선형 함수로는 ReLU, GELU
Feed Forward Network는 모든 위치에 동일한 방식으로 적용되지만, 각 레이어마다 독립적인 파라미터를 사용
입력과 출력의 차원은 d_model = 512, 중간 차원은 d_ff = 2048을 사용
FFN은 encoder나 decoder의 self-attention layer 이후에 위치하며, multi-head attention을 통해 계산된 각 위치의 context 표현을 feature 차원에서 비선형적으로 변환하고 다시 투영(projection)하여, 더 복잡한 표현을 학습하는 역할
Residual Block & Layer Normlization
각 Encoder의 각 sub layer(self-attention, feed forward)에는 residual connection이 포함되어 있고 layer-normlization단계가 있음
Residual Block을 적용하면 backpropagation에서 gradient를 항상 1이상으로 유지하기에 더 잘 보존함
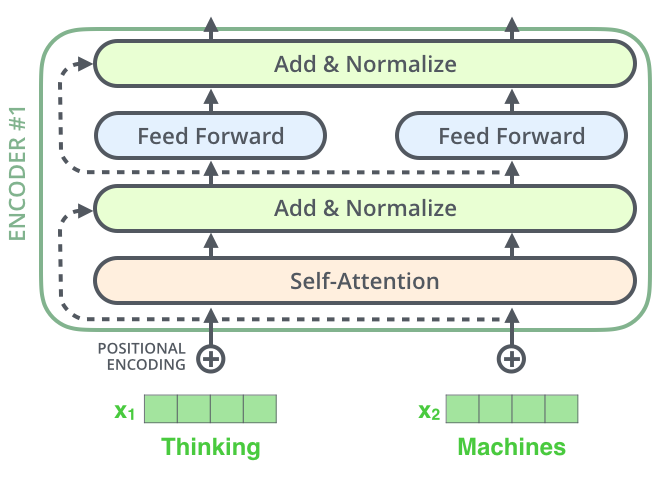
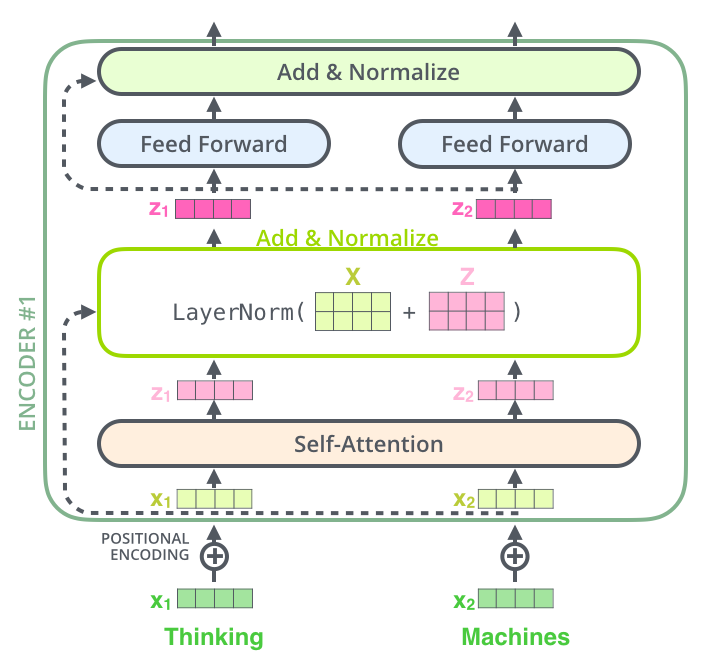
Decoder
Decoder가 동작을 수행하기 위해서는 Encoder는 입력 시퀀스를 처리하고 전달하기 위한 K,V를 생성, Encoder로부터 추출된 입력 시퀀스의 representation K, V는 decoder layer의 encoder-decoder attention sublayer에 전달
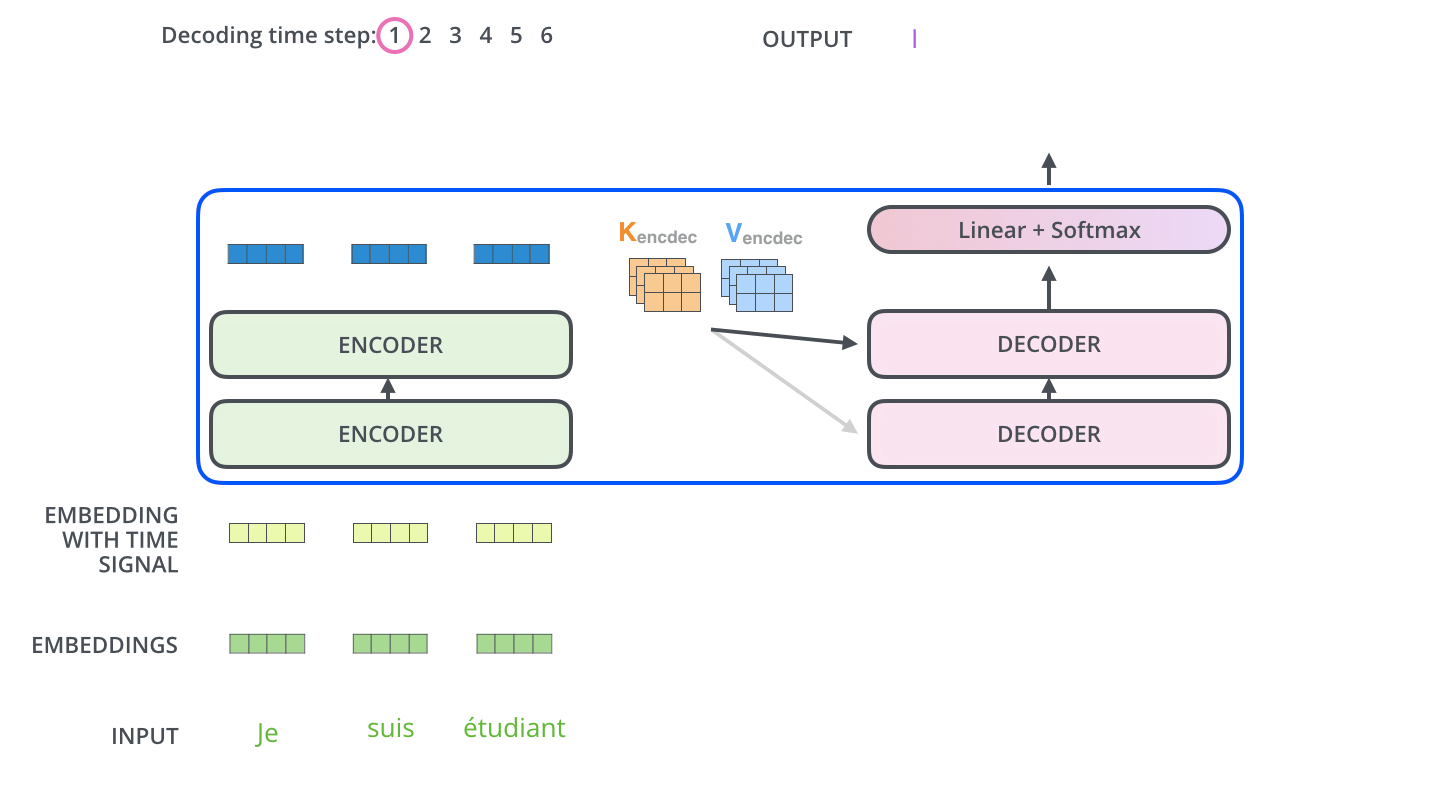
decoder가 매 스텝마다 출력을 생성하고 출력 완료 신호인
decoder의 입력은 한 칸씩 오른쪽으로 shift된 값이 들어가게 되고 현재 위치에서 이전 위치에 대해서믄 attention을 수행해야하므로 현재 이후 위치에 대해서는 dot product 결과에 -∞로 마스킹
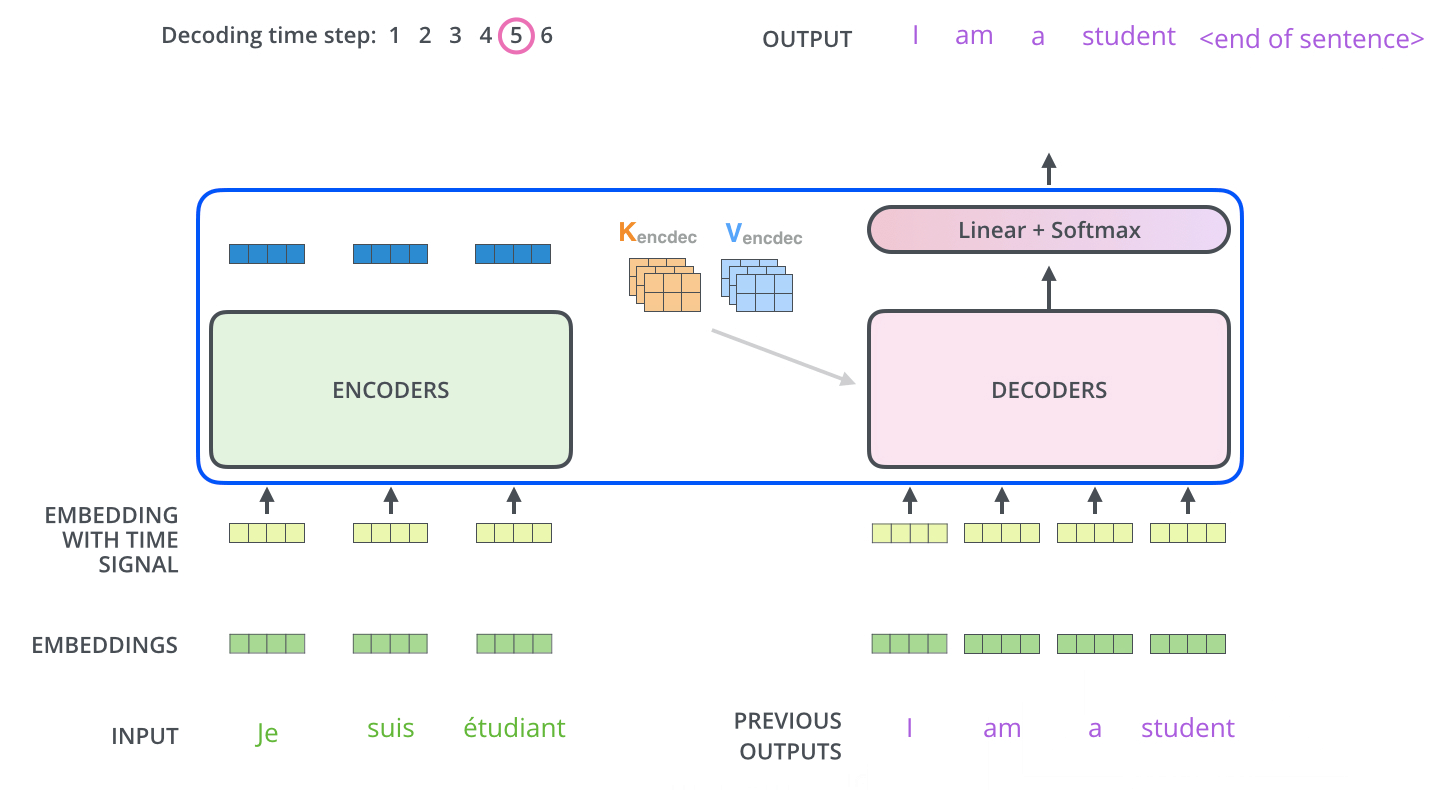

- Decoder: self-attention이 출력 시퀀스에서 이전 위치에만 주의를 기울일 수 있고 소프트맥스 단계 이전에 마스킹을 수행
- Encoder-Decoder Attetnion은 mluti-headed self-attention과 동일하게 작동하지만 Queries matrix는 하위 레이어로부터 생성하고, Key and Values는 Encodr에서 가져옴
The Final Linear and Softmax Layer
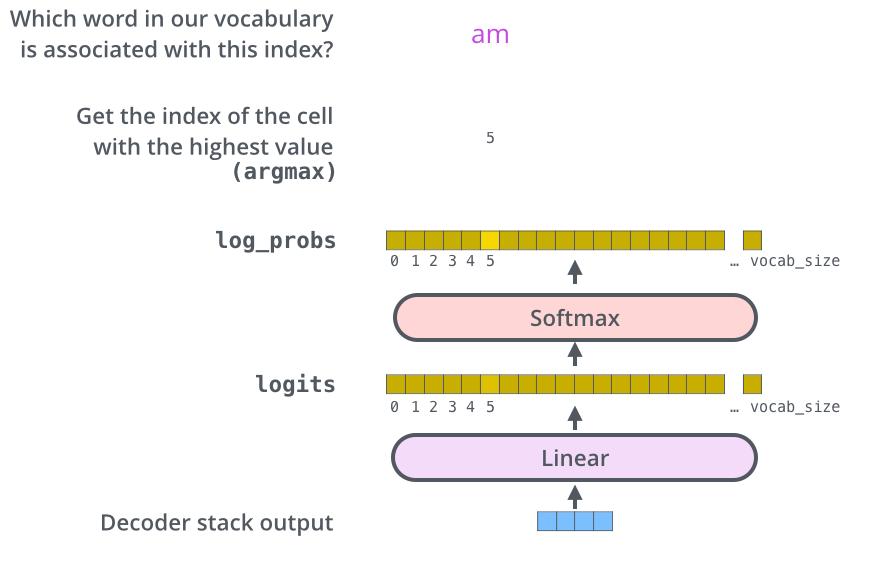
Decoder stakck은 vector of floats를 출력하는데 단어로 바꾸는 역할이 Linear, Softmax
- Linear: Decodr Stack에서 나온 vector를 훨씬 더 큰 vector인 logits으로 변환하는 simple fully connected neural network
- 모델이 학습 데이터 세트를 통해 10,000개의 고유한 영어 단어(모델의 출력 어휘)를 알고 있다면 로짓 벡터는 10,000차원이 됨
- 이 벡터의 각 셀은 하나의 고유한 단어에 대한 점수를 타나냄
- 이 과정을 통해 Linear layer 이후의 모델 출력을 해석 가능
- Softmax: 이러한 점수를 모두 양수이고 합이 1.0이 되도록 확률로 변환, 확률이 가장 높은 셀을 선택하고 그 셀에 해당하는 단어가 해당 time step의 출력으로 생성됨
