DL| FCN의 Receptive Field를 개선한 DeepLabv1, DilatedNet 정리
FCN의 Receptive Field 문제를 해결하기 위한 기법으로 Dilated Convolution을 도입하고, 이를 기반으로 설계된 DeepLab v1과 DilatedNet의 구조와 특징, CRF 기반 후처리를 통한 정교한 예측 향상 방식
DeepLabv1 리뷰 DeepLab의 Atrous CNN DeepLab(2) Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials BoostCampAITECH
FCN의 한계점
- 객체의 크기가 크거나 작은 경우 예측을 잘 하지 못함
- 큰 오브젝트의 경우 지역적인 정보만으로 예측함: 유리창에 비친 자전거를 인식하는 문제
- 같은 오브젝트여도 다르게 라벨링
- 작은 오브젝트 무시
- Object의 디테일한 모습이 사라지는 문제
- Deconvolution 절차가 간단해서 경계를 학습하기에 어려움
이러한 문제를 해결하기 위한 방법으로 Decoder 개선, Skip Connection 적용, Receptive Field 확장한 모델들에 대해서 살펴봄
Receptive Field를 확장시킨 모델
Receptive Filed(소용 영역)란? CNN에서 출력 레이어의 뉴런 하나에 영향을 미치는 입력 뉴런들의 공간 크기로 각 뉴런이 보고 처리하는 입력 이미지의 영역
- 서로 다른 receptive field를 가진다면 작을 경우 새에 대한 정보를 부분적으로 포함하고, 클 경우 새에 대한 정보를 모두 포함하게 됨
- 객체가 클 경우 receptive filed가 정보를 다 포함하지 못하므로 예측 정확도가 낮음
→ 넓은 receptive filed를 확보하는 것이 모델의 성능에 큰 영향을 미칠 것이라고 생각
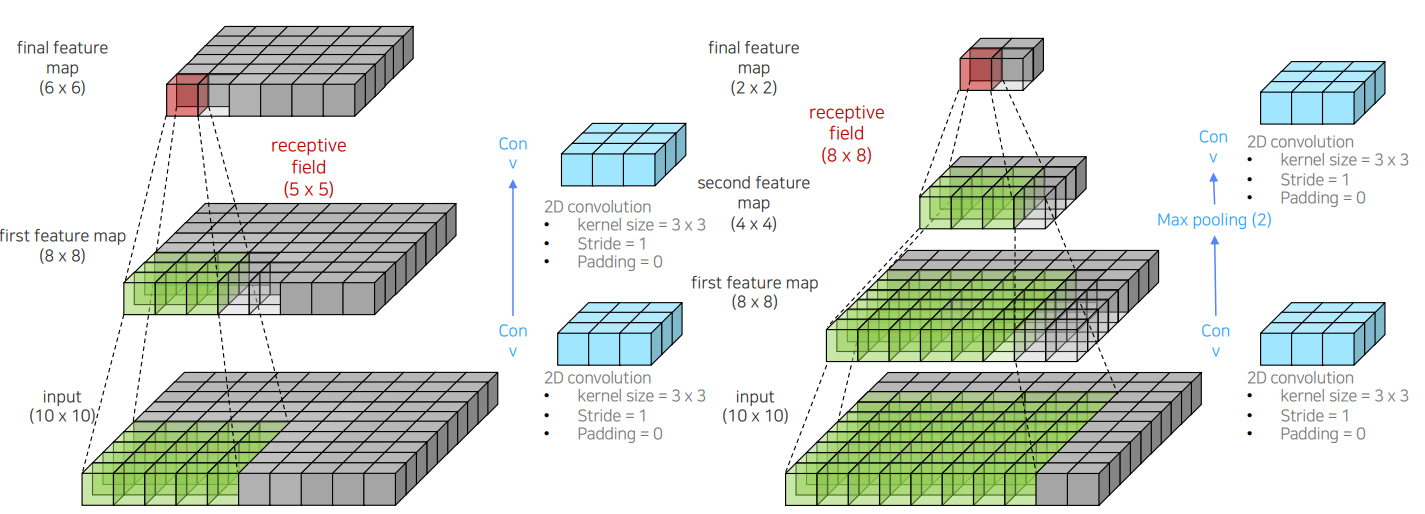
Conv → Max Pooling → Conv 연산을 반복하면 효율적으로 receptive filed를 넓힐 수 있는데 Resolution 측면에서는 low feature resolution을 가지는 문제점이 발생함
이미지의 크기는 많이 줄이지 않으면서 파라미터 수도 변함 없고, Receptive filed만 넓게하는 방식없을까? → Dilated Convolution
Dilated Convolution
== atrous convolution == hole algorithm
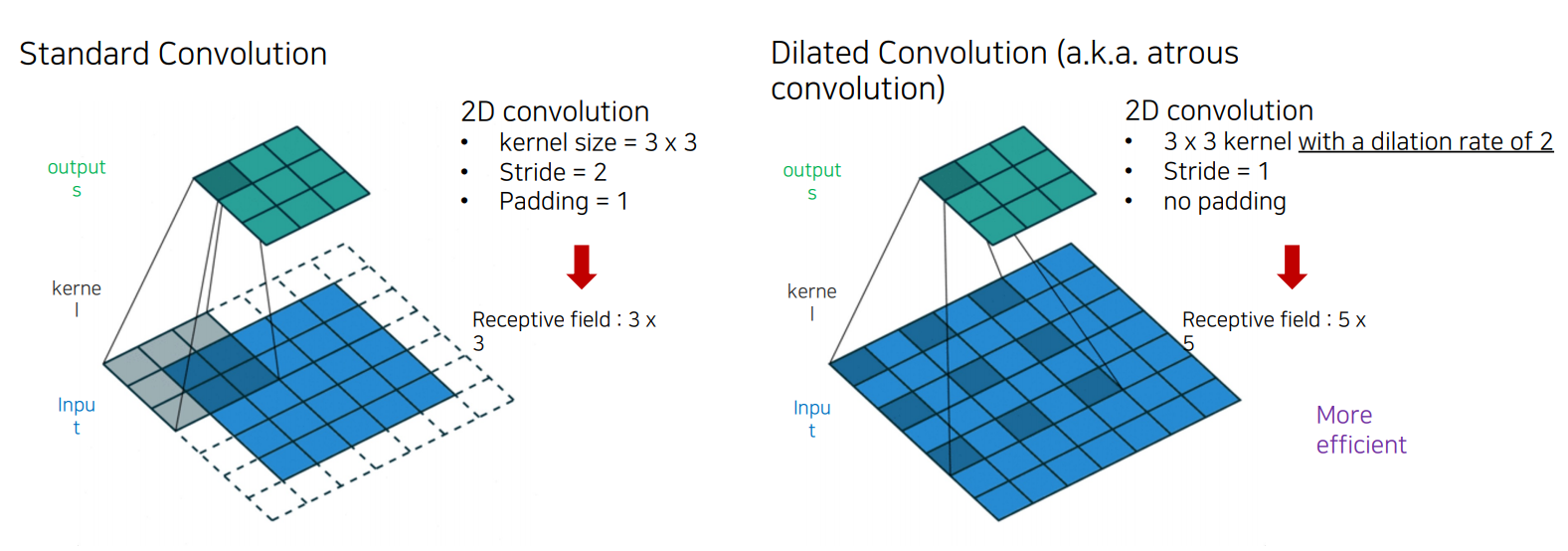
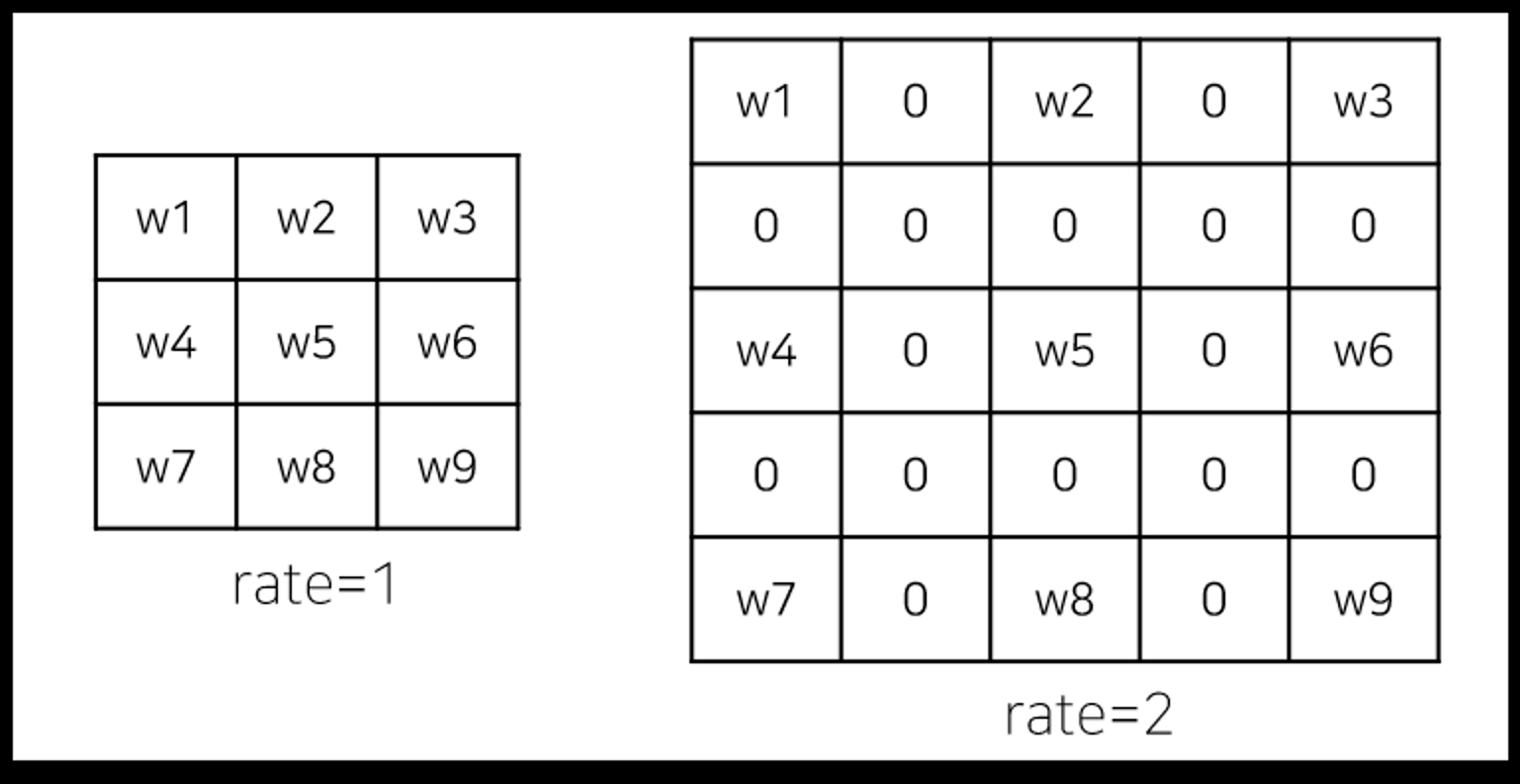
dilation rate 커널 사이의 간격을 정의하는 파라미터를 도입하였고 dilation rate가 2인 3x3 커널은 9x9의 파라미터를 사용하면서 5x5 커널과 동일한 view를 가짐
5x5 커널을 사용하고 두번째 열과 행을 모두 삭제하면(3x3 커널을 사용한 경우 대비) 동일한 계산 비용으로 더 넓은 시야를 제공함
→ Real-Time semgnetaion에서 주로 사용됨, 넓은 시야가 필요하고 여러 convolution이나 큰 커널을 사용할 여유가 없는 경우에 사용
DeepLab v1
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
아키텍쳐
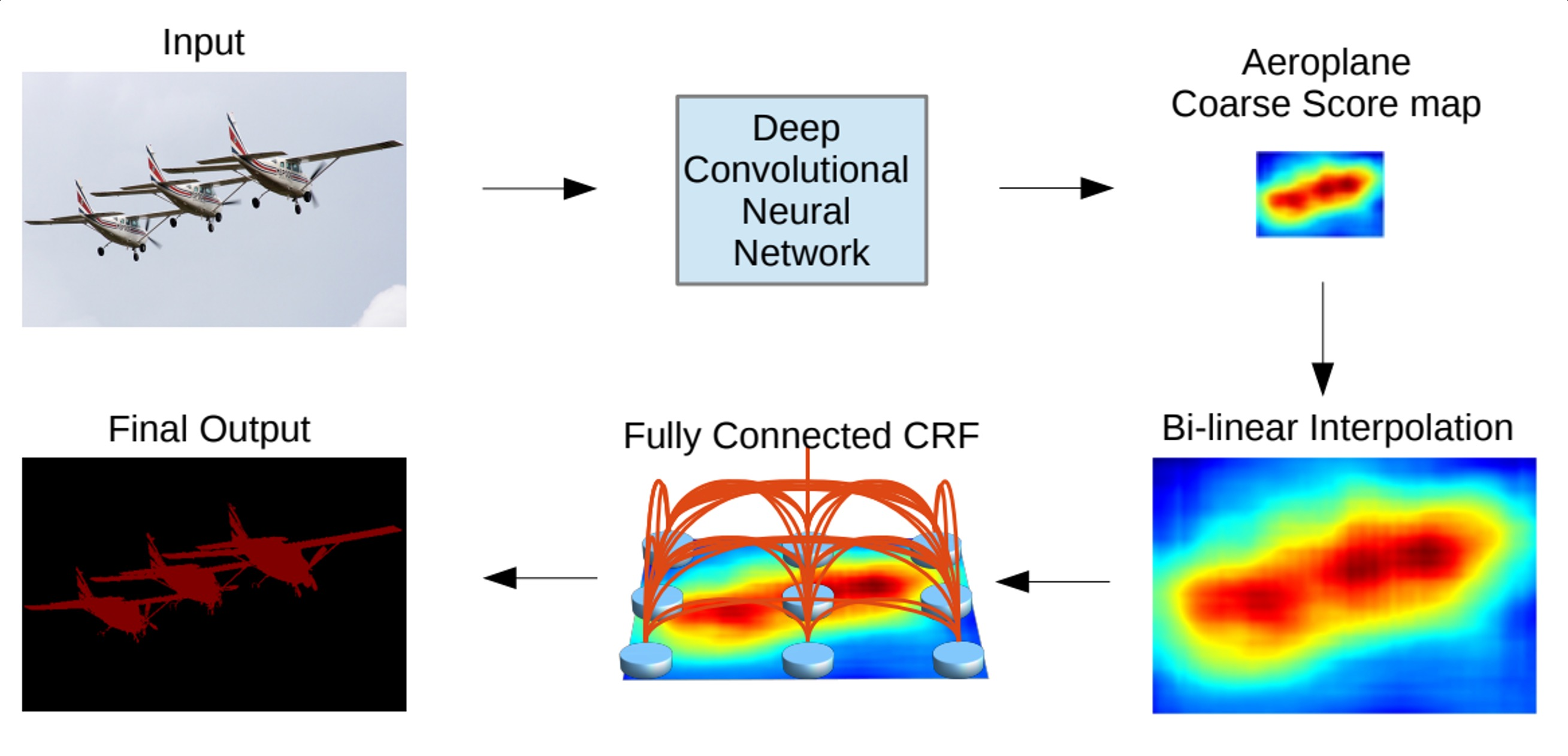
CRF는 주변의 상태에 따라 현재의 상태를 결정하는 알고리즘으로, 각 변수의 독립성이 보장되지 않아도 되는 장점이 있는데 CNN만으로는 Segmentation이 잘되지 않아서 CNN과 CRF를 결합하여 문제를 해결했으며, Hole algorithm을 도입을 통해서 빠른 CNN 계산이 가능하도록 함
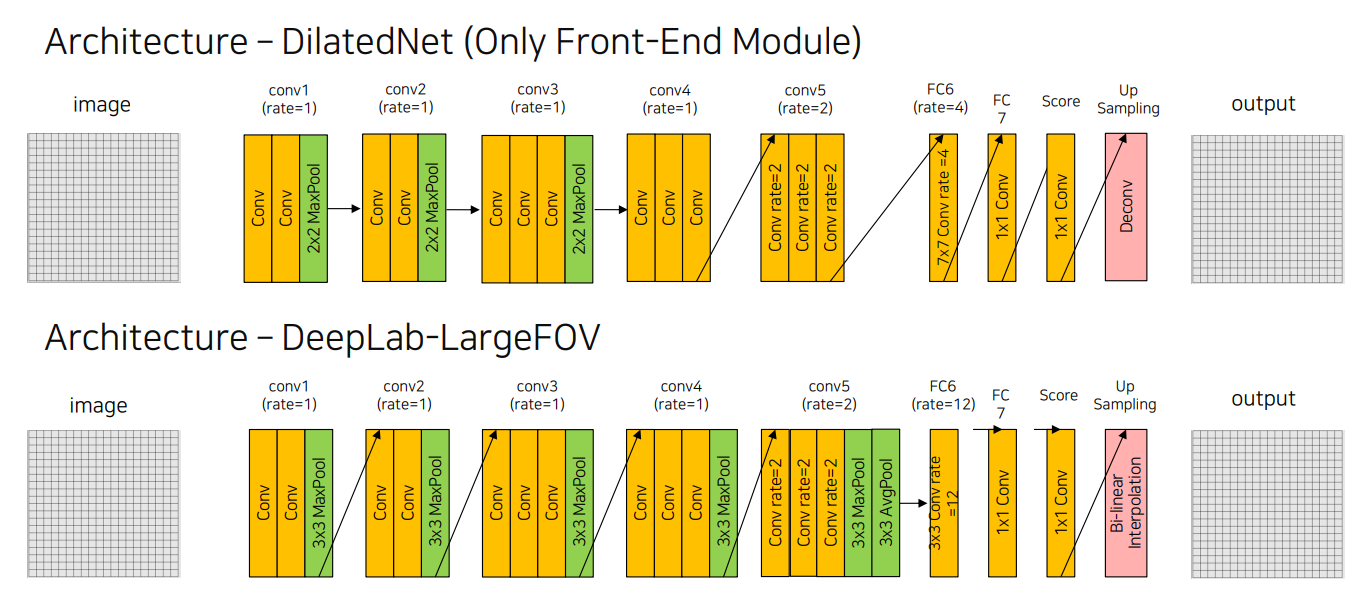
아래는 DeepLab v1-Large FOV의 전체적인 구조로 VGG 16을 수정하여 구현

conv5에서부터 dilated convolution을 적용하였고, feature map의 크기가 입력 이미지 대비 1/8로 축소되었기 때문에 마지막의 Bi-linear interpolation을 통해서 원본과 동일한 resolution으로 만들어줌
x = F.interpolate(x, size=(feature_map_h * 8, feature_map_w * 8), mode="bilinear")
아래 사진은 간단한 bilinear interpolation 예시
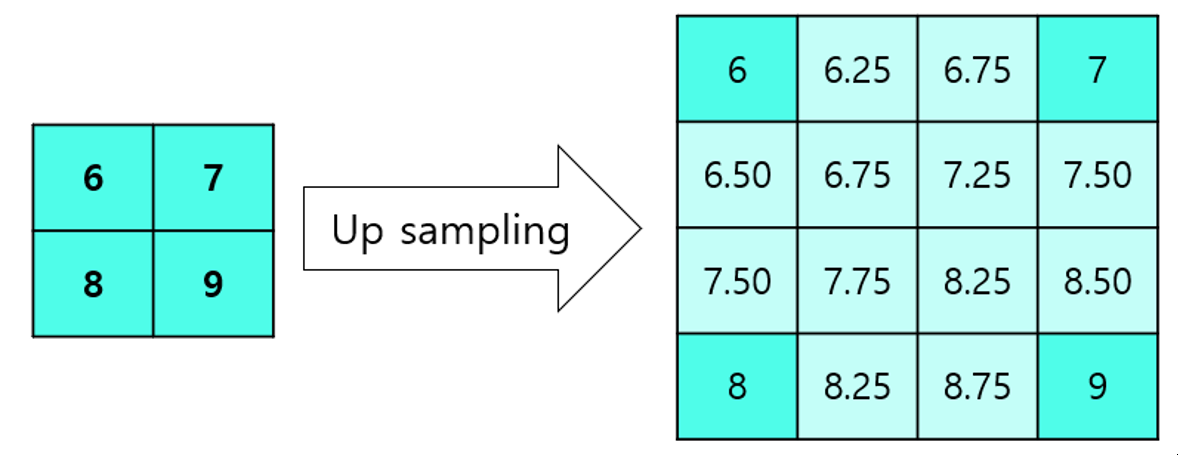
해당 코드에서 align_corners의 값에 따라 결과가 달라지므로 주의

마지막에 bilinear interpolation으로 인해서 픽셀 단위의 정교한 segmentation이 불가능
→ Dense CRF 후처리 알고리즘을 적용
CRF, Dense CRF
- CRF(Conditional Random Field): 일반적으로 short-range CRF는 segmentation을 수행한 뒤에 생기는 잡음을 없애는 용도로 많이 사용되었음
- Dense CRF(Dense Conditional Random Field == Fully-Connected CRF): 전체 픽셀을 모두 연결한 CRF 방법임
이미 conv+pooling의 단계를 거쳐서 크기가 작아지고 upsampling해서 이미 smooth한 상태인데 기존처럼 short-range CRF를 사용하면 결과가 더 나빠지므로 Dense CRF를 적용
Dense CRF에 MCMC(Markov Chain Monte Carlo) 방식을 사용하면 좋은 결과를 얻을 수 있지만 시간이 오래걸려서 mean filed approximation 방법을 적용하여 message passing을 사용한 iteration 방법을 적용함
mean filed approximation 방법? 물리학이나 확률 이론에서 많이 사용되는 방법, 복잡한 모델을 설명하기 위해서 더 간단한 모델을 선택하는 방식
많은 변수들로 이뤄진 복잡한 관계를 갖는 상황에서 특정 변수와 다른 변수들의 관계의 평균을 취하면 평균으로부터 변화(fluctuation)을 해석하는데도 용이하고 평균으로 단순화된 또는 근사된 모델을 사용시 전체를 조망하기에 좋아짐
Dense CRF는 다음의 에너지 함수 E(x)를 최소화
- unary potential, pairwise potential로 구성되어있음
- x는 각 픽셀의 위치에 해당하는 픽셀의 label이고, i, j는 픽셀의 위치
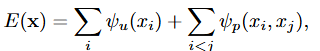
- unary potential
- 픽셀 i가 라벨 x_i일 확률의 음의 로그로 정의됨
- P(x): CNN의 출력에서 softmax 확률
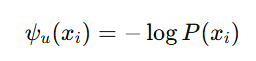
- pairwise potential
- 픽셀 i, j의 라벨 관계에 대한 비용으로 다음과 같은 형태를 가짐
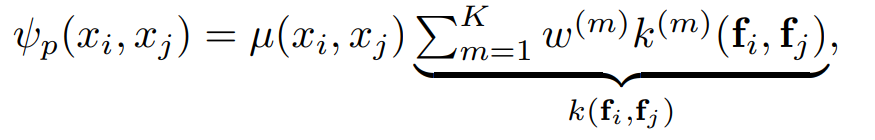
대표적인 커널은 2개

- apperance kernel
- 색상이 유사하고 인접한 픽셀들이 같은 클래스에 속할 가능성이 높다는 관찰에서 착안되어 위치가 가깝고 색상도 비슷한 픽셀 쌍에 큰 유사도를 부여
- 는 픽셀의 위치, 는 픽셀의 컬러값
- 인접성과 색상 유사도의 정도는 와 에 의해서 제어
- smoothness kernel
- 색상과 무관하게 위치 기반으로 전반적인 클래스 smoothness 유도를 통해 작은 고립 영역을 제거하는 역할을 함
- : 거리 기반 감쇠 파라미터
이를 고속으로 처리하기 위해서 Philipp Krahenbuhl 방식을 사용하게 되면 feature space에서는 Gaussian convolution으로 표현할 수 있게 되어서 고속 연산이 가능해짐
정리
- DCNN을 이용해서 1/8 크기의 coarse score-map을 구함
- Bi-linear interpolation을 통해 원영상 크기로 확대
- Bilinear interpolation을 통해 얻어진 결과는 각 픽셀 위치에서 label에 대한 확률이 됨
- 이는 CRF의 unary term에 해당
- 최종적으로 모든 픽셀 위치에서 pairwise term까지 고려한 CRF 후보정 작업을 해주면 최종적인 출력 결과를 얻음
DilatedNet
전체구조를 DeepLab-LargeFOV와 비교
- Conv4, Conv5 block에서 maxpool, avgpool을 사용하지 않았지만 이후 7x7 dilated convolution 연산을 수행
- bilinear interpolation이 아닌 Deconv Layer를 사용
다양한 dilation rate를 사용하는 Basic Context Module를 추가로 구성해서 다양한 범위의 Receptive filed를 이용했을 때 성능 향상이 있었음

