ML| 데이터 전처리
데이터 전처리 튜토리얼
‘파이썬 머신러닝 완벽가이드(권철민 지음)’, 통계: 정규화와 표준화
사이킷런의 머신러닝 알고리즘은 문자열 값을 입력 값으로 인정하지 않습니다. 그래서 숫자형으로 변환해야합니다.
- 문자열 피처: 카테고리형, 텍스트형
- 카테고리: 코드 값
- 텍스트: 피처 벡터화등의 기법 OR 불필요한 피처 삭제
데이터 인코딩
머신러닝을 위한 대표적인 인코딩 방식은 레이블, 원-핫 인코딩이 있습니다.
레이블 인코딩(Label Encoding)
카테고리 피처를 코등형 숫자 값으로 변환합니다.
from sklearn.preprocessing import LabelEncoder
fit()과 transform()을 호출해 레이블 인코딩을 수행합니다. inverse_transform()을 통해 인코딩된 값을 다시 디코딩할 수 있습니다.
레이블 인코딩이 일괄적인 숫자 값으로 변환되면서 숫자 값의 크고 작음에 대한 특성 때문에 몇몇 ML 알고리즘에는 성능이 떨어지는 경우가 발생합니다.
-> 원-핫 인코딩
원-핫 인코딩(One-Hot Encoding)
피처 값의 유형에 따라 새로운 피처를 추가해 고유 값에 해당하는 칼럼에만 1을 표시하고 나머지를 0으로 표시하는 방식입니다.
from sklearn.preprocessing import OneHotEncoder
주의할 점
- OneHotEncoder로 변환하기 전에 모든 문자열 값이 숫자형 값으로 변환되어 있어야합니다.
- 입력 값으로 2차원 데이터가 필요합니다.
pandas-get_dummies()
사이킷런의 OneHotEncoder와 다르게 문자열 카테고리 값읠 숫자 형으로 변환할 필요없이 바로 변환할 수 있습니다.
pd.get_dummies(df)
피처 스케일링과 정규화
피처 스케일링: 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업입니다. 데이터의 범위 재조정이 필요한 이유는 데이터의 범위가 너무 넓은 곳에 퍼져있을 때(scale이 크다면), 데이터셋이 outlier를 지나치게 반영하여 오버피팅이 될 가능성이 높기 때문입니다. 대표적으로 표준화(Standardization), 정규화(Normalization)가 있으며 scale 조절 방식에 차이가 존재합니다.
표준화(Standardization)
데이터의 피처 각각이 평균이 0이고 분산이 1인 가우시안 분포를 가진 값으로 변환하는 것을 의미합니다.
표준화는 예측 성능 향상에 중요한 요소입니다.
0 주위에 표준편차 1의 값으로 배치되도록 피처를 표준화하면 다른 단위를 가진 측정값을 비교할 때 중요할 뿐만 아니라 많은 기계 학습 알고리즘의 일반적인 요구사항입니다. 사이킷런에서 RBF 커널을 이용한 서포트 벡터 머신, 선형 회귀, 로지스틱 회귀는 가우시안 분포를 가지고 있다고 가정되어 있기도 합니다.
경사하강법을 예로 들면 피처들이 각각 다른 척도에 있으면, 피처값 가 가 업데이트 되도록 가중치 업데이트 역할을 하기 때문에 특정 가중치가 다른 가중치보다 더 빨리 업데이트 될 수 있습니다. 피처값의 범위가 비슷하면 경사하강법은 더 빠르게 최저값으로 수렴합니다.
- : lr, : target label, : output
최솟값과 최댓값의 크기를 제한하지 않기 때문에 이상치를 파악할 수 있습니다. Z-score을 구함으로써 데이터가 평균으로부터 얼마나 떨어져있는지 구하고, 특정 범위를 벗어나면 이상치로 간주해 제거할 수 있습니다.
Z-점수 정규화로 스케일링이 되는 이유: 체비셰프 부등식(Chebyshev’s Inequality)
평균과 표준편차를 이용하는 z-점수가 데이터들을 특정 범위 안으로 반드시 스케일링 시킬 수 있을까?
만약 데이터가 정규 분포를 따른다면, 범위 [-3, 3] 안에 99.7%의 데이터가 있는 것을 표준정규분포표로부터 쉽게 알 수 있습니다. 하지만 만약 데이터가 정규분포를 따르지 않는다면?
데이터가 정규분포를 따르지 않는 경우에도 체비셰프 부등식(Chebyshev’s Inequality)은 범위 [-4, 4] 안에 최소 94%의 데이터가 있는 것을 보장합니다. 체비셰프 부등식은 다음과 같습니다.
- 이 부등식으로부터 z-점수 정규화를 적용했을 때 특정 범위 안으로 데이터들을 스케일링할 수 있는 것을 어느 정도 보장합니다.
사이킷런 StandardScaler
가우시안 정규 분포를 가질 수 있도록 데이터를 변환해줍니다.
from sklearn.preprcoessing import StandardScaler
fit()과 transform()을 이용해 변환합니다.
정규화(Normalization)
데이터셋의 numerical value 범위의 차이를 왜곡하지 않고 공통 척도로 변경하는 것입니다. 기계학습에서 모든 데이터셋이 정규화 될 필요는 없고, 피처의 범위가 다른 경우에만 필요합니다.
데이터의 정규화가 필요한 이유는 데이터 feature간 차이가 심하게 날 때, 큰 범위를 가지는 feature(ex. 가격)가 작은 범위를 가지는 feature(ex.나이)보다 더 강하게 모델에 반영될 수 있기 때문입니다.
따라서 정규화를 통해 피처 벡터의 유클리디안 길이가 1이 되도록 데이터 포인트를 조정합니다. (지름이 1인 원(3차원이라면 구)에 데이터 포인트를 투영) 즉, 각 데이터 포인트가 다른 비율로 스케일이 조정된다는 것입니다. 이러한 정규화는 특성 벡터의 길이는 상관 없고 데이터의 방향만이 중요할 때 많이 사용합니다.
- 장점
- 학습속도 개선
- 노이즈가 작아져 오버피팅 억제
- 데이터가 덜 치우쳐, 좋은 성능
사이킷런 Normlizer
일반적인 정규화와는 차이가 있습니다. 큰 개념은 같지만 선형대수에서의 정규화 개념이 적용되었습니다. 개별 벡터의 크기를 맞추기 위해 변환하는 것을 의미합니다. 즉, 개별 벡터를 모든 피처 벡터의 크기로 나눠줍니다. (유클리디안 거리로 계산하는 방법)
-> 만약 x, y, z의 피처가 있을 때
머신러닝 완벽가이드에서는 일반적인 의미의 표준화외 정규화를 피처 스케일로 통칭, 선형대수 개념의 정규화를 벡터 정규화로 지칭
Min-Max Scaling
모든 피처가 정확하게 [0, 1] 사이에 위치하도록 데이터를 변경합니다.
Min-Max Scaling은 정규화를 하는 하나의 방법
사이킷런 MinMaxScaler
데이터 값을 0과 1사이의 범위 값으로 변환합니다. 음수 값이 있으면 -1에서 1값으로 변환합니다. 데이터 분포가 가우시안 분포가 아닐 경우 min, max scale을 적용해 볼 수 있습니다.
from sklearn.preprcoessing import MinMaxScaler
fit()과 transform()을 이용해 변환합니다.
데이터 스케일링 변환 시 유의점
StandardScaler나 MinMaxScaler와 같은 Scaler 객체 사용 시 fit(), transform(), fit_transform() 메소드를 이용합니다.
- fit(): 데이터 변환을 위한 기준 정보 설정(ex. min/max)
- transform(): fit으로 설정된 정보를 이용해 데이터 변환
- fit_transform(): 동시에
Scaler 객체를 이용하여 학습 데이터로 fit(), transform()을 적용하면 테스트 데이터 세트로는 다시 fit()을 수행하지 않고 학습 데이터 세트로 fit()을 수행한 결과를 이용해서 transform()을 적용해야 합니다.
-> 테스트 데이터로 다시 만들 경우 스케일링 기준 정보가 달라져 올바른 예측 결과를 도출할 수 없습니다.
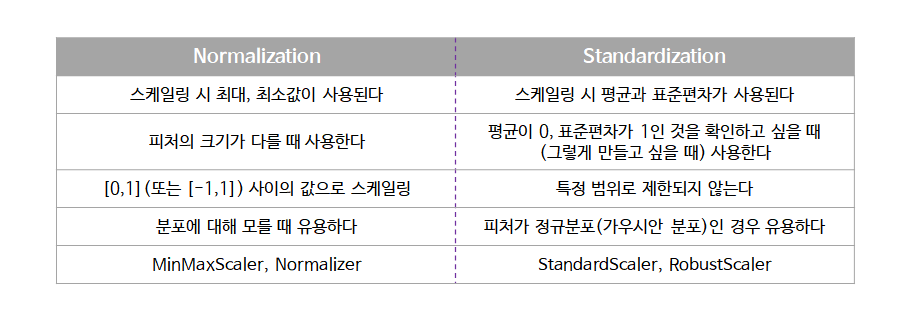
Normalization VS Standardization
보통 표준화를 통해 이상치를 제거하고, 그 다음 데이터를 정규화해서 상대적 크기에 대한 영향력을 줄인 뒤 분석을 시작합니다.